1、题干
你打算做甜点,现在需要购买配料。目前共有 n 种冰激凌基料和 m 种配料可供选购。而制作甜点需要遵循以下几条规则:
- 必须选择 一种 冰激凌基料。
- 可以添加 一种或多种 配料,也可以不添加任何配料。
- 每种类型的配料 最多两份 。
给你以下三个输入:
baseCosts,一个长度为n的整数数组,其中每个baseCosts[i]表示第i种冰激凌基料的价格。toppingCosts,一个长度为m的整数数组,其中每个toppingCosts[i]表示 一份 第i种冰激凌配料的价格。target,一个整数,表示你制作甜点的目标价格。
你希望自己做的甜点总成本尽可能接近目标价格 target 。
返回最接近 target 的甜点成本。如果有多种方案,返回 成本相对较低 的一种。
示例 1:
输入:baseCosts = [1,7], toppingCosts = [3,4], target = 10
输出:10
解释:考虑下面的方案组合(所有下标均从 0 开始):
- 选择 1 号基料:成本 7
- 选择 1 份 0 号配料:成本 1 x 3 = 3
- 选择 0 份 1 号配料:成本 0 x 4 = 0
总成本:7 + 3 + 0 = 10 。
示例 2:
输入:baseCosts = [2,3], toppingCosts = [4,5,100], target = 18
输出:17
解释:考虑下面的方案组合(所有下标均从 0 开始):
- 选择 1 号基料:成本 3
- 选择 1 份 0 号配料:成本 1 x 4 = 4
- 选择 2 份 1 号配料:成本 2 x 5 = 10
- 选择 0 份 2 号配料:成本 0 x 100 = 0
总成本:3 + 4 + 10 + 0 = 17 。不存在总成本为 18 的甜点制作方案。
示例 3:
输入:baseCosts = [3,10], toppingCosts = [2,5], target = 9
输出:8
解释:可以制作总成本为 8 和 10 的甜点。返回 8 ,因为这是成本更低的方案。
示例 4:
输入:baseCosts = [10], toppingCosts = [1], target = 1
输出:10
解释:注意,你可以选择不添加任何配料,但你必须选择一种基料。
提示:
n == baseCosts.lengthm == toppingCosts.length1 <= n, m <= 101 <= baseCosts[i], toppingCosts[i] <= 1041 <= target <= 104
Problem: 1774. 最接近目标价格的甜点成本
2、思路
暴力搜索,确定基料,枚举配料
3、Code
function closestCost(baseCosts: number[], toppingCosts: number[], target: number): number {
let ans = baseCosts[0];
function dfs(c: number, ti: number) {
if (c === target) return ans = target;
else {
const d1 = Math.abs(c - target), d2 = Math.abs(ans - target);
if (d1 < d2 || (d1 === d2 && c < ans)) ans = c;
}
for (let i = ti; i < toppingCosts.length && c <= target; i++) {
for (let k = 0; k < 3; k++) dfs(c + k * toppingCosts[i], i + 1);
}
}
for (const b of baseCosts) dfs(b, 0);
return ans;
};
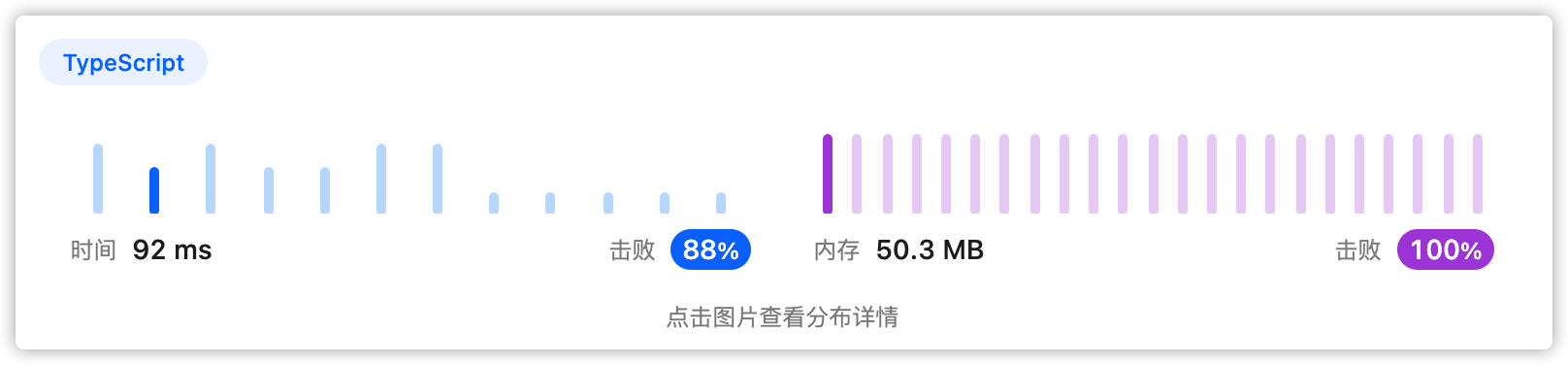
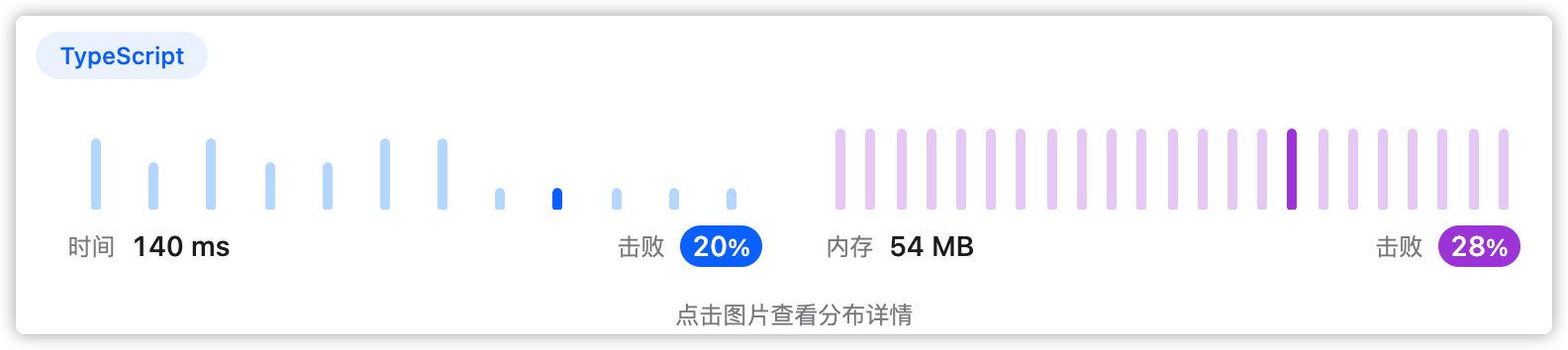
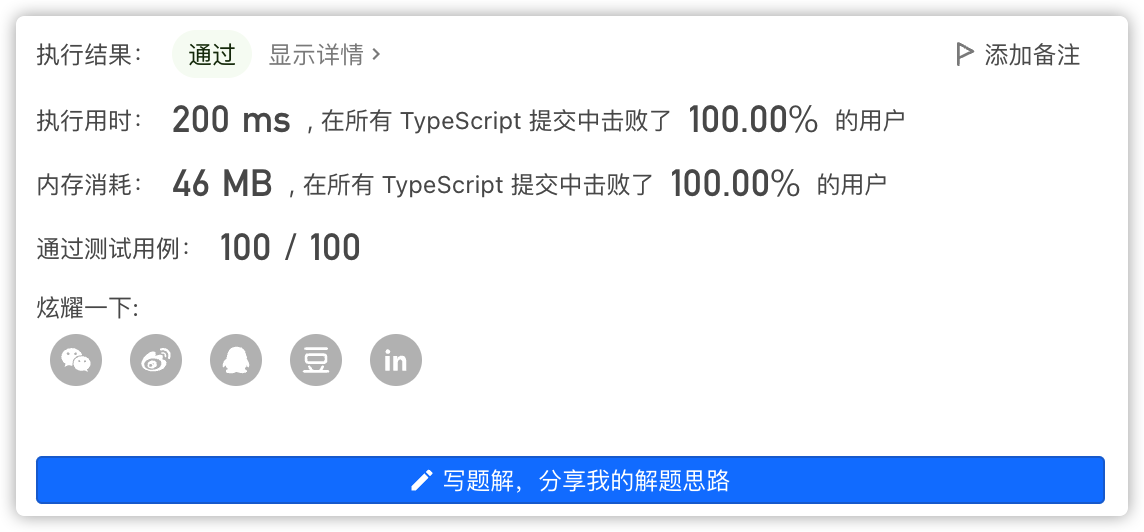
4、执行结果