1、题干
你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。
如果文件夹 folder[i] 位于另一个文件夹 folder[j] 下,那么 folder[i] 就是 folder[j] 的 子文件夹 。
文件夹的「路径」是由一个或多个按以下格式串联形成的字符串:'/' 后跟一个或者多个小写英文字母。
- 例如,
"/leetcode"和"/leetcode/problems"都是有效的路径,而空字符串和"/"不是。
示例 1:
输入:folder = ["/a","/a/b","/c/d","/c/d/e","/c/f"]
输出:["/a","/c/d","/c/f"]
解释:"/a/b" 是 "/a" 的子文件夹,而 "/c/d/e" 是 "/c/d" 的子文件夹。
示例 2:
输入:folder = ["/a","/a/b/c","/a/b/d"]
输出:["/a"]
解释:文件夹 "/a/b/c" 和 "/a/b/d" 都会被删除,因为它们都是 "/a" 的子文件夹。
示例 3:
输入: folder = ["/a/b/c","/a/b/ca","/a/b/d"]
输出: ["/a/b/c","/a/b/ca","/a/b/d"]
提示:
1 <= folder.length <= 4 * 1042 <= folder[i].length <= 100folder[i]只包含小写字母和'/'folder[i]总是以字符'/'起始folder每个元素都是 唯一 的
2、思路1-排序
- 对文件夹数组
folder升序排序,初始化父文件夹pf = folder[0] + '/' - 遍历检查所有文件夹
folder[i]与当前父文件夹pf是否父子关系,是则说明folder[i]是子文件夹,不是则将folder[i]置为父文件夹继续检查
3、代码
function removeSubfolders(folder: string[]): string[] {
folder.sort();
const ans = [folder[0]];
let pf = folder[0] + '/';
for (let i = 1; i < folder.length; i++) {
if (!folder[i].startsWith(pf)) {
ans.push(folder[i]);
pf = folder[i] + '/';
}
}
return ans;
};
4、复杂度
- 时间复杂度:
- 空间复杂度:
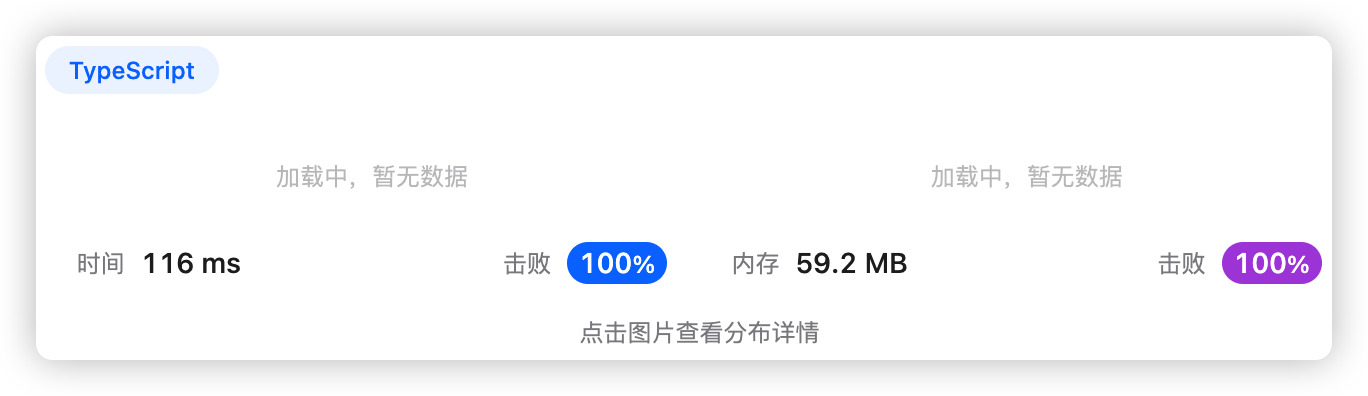
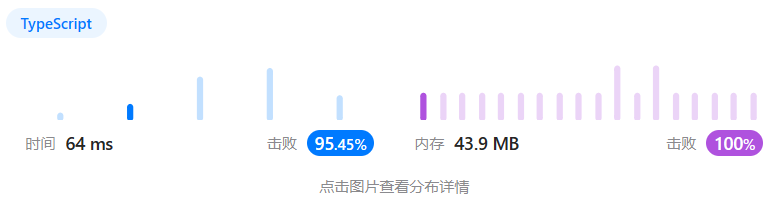
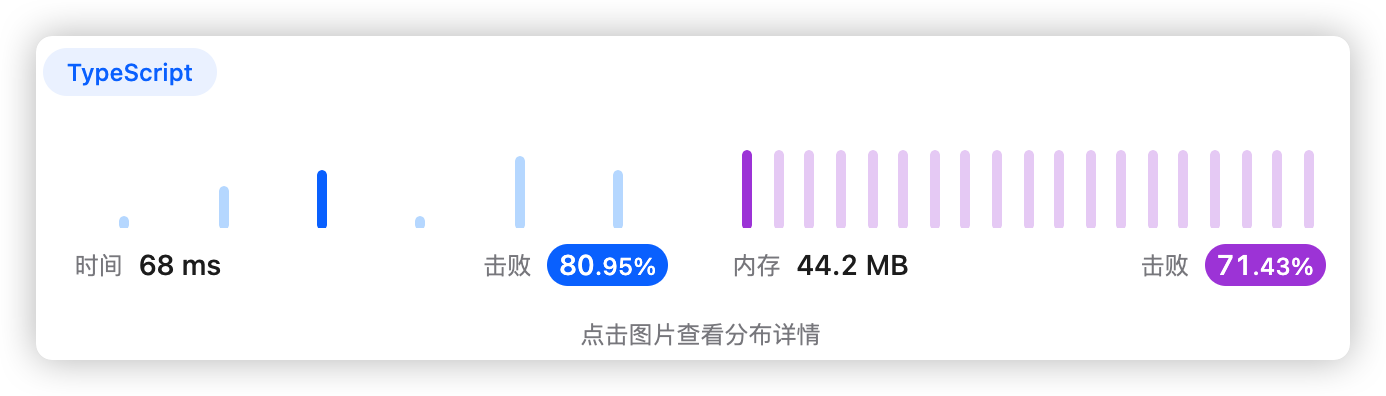
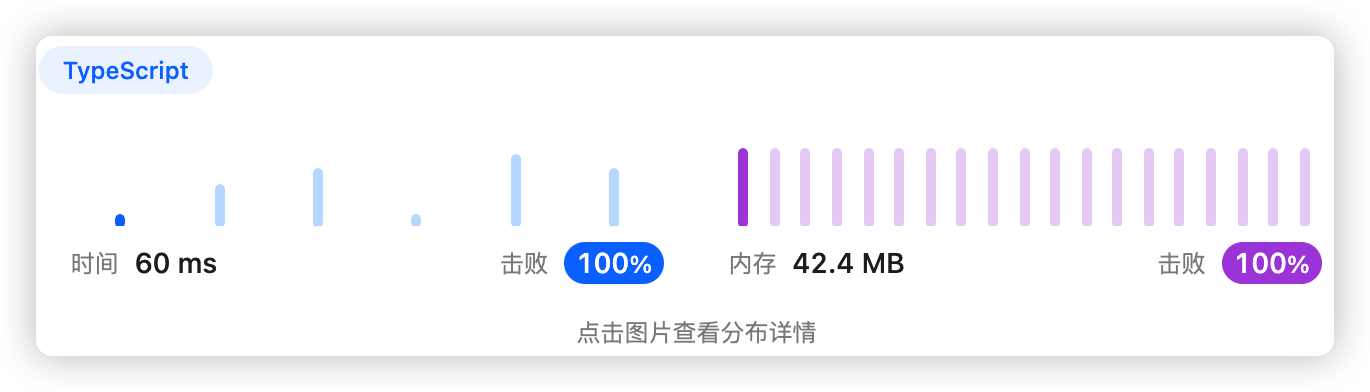
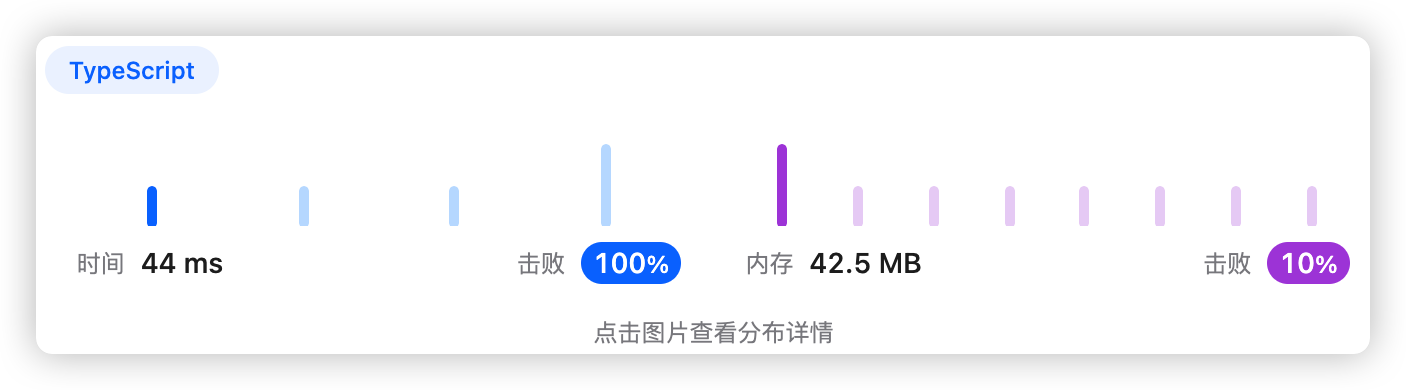
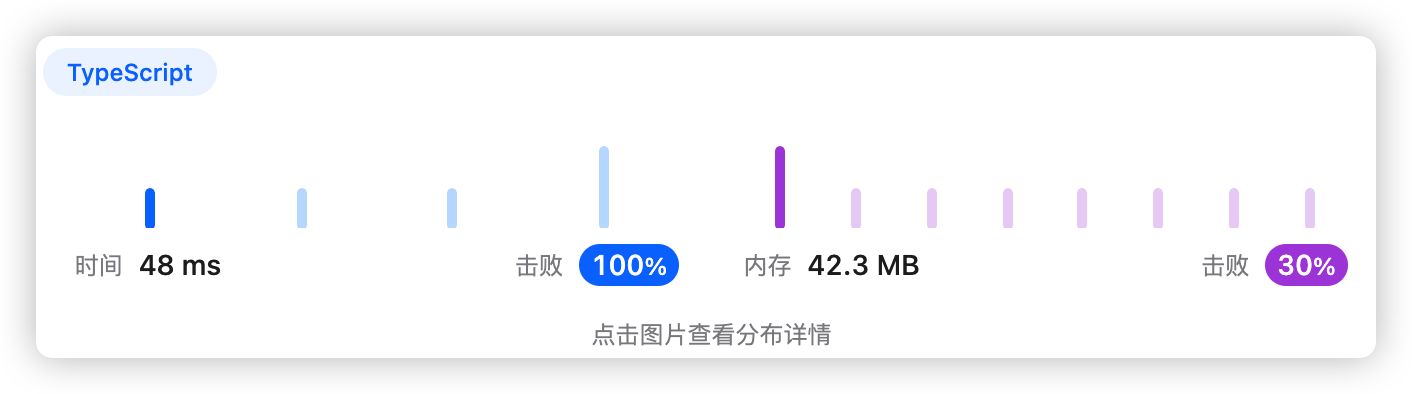
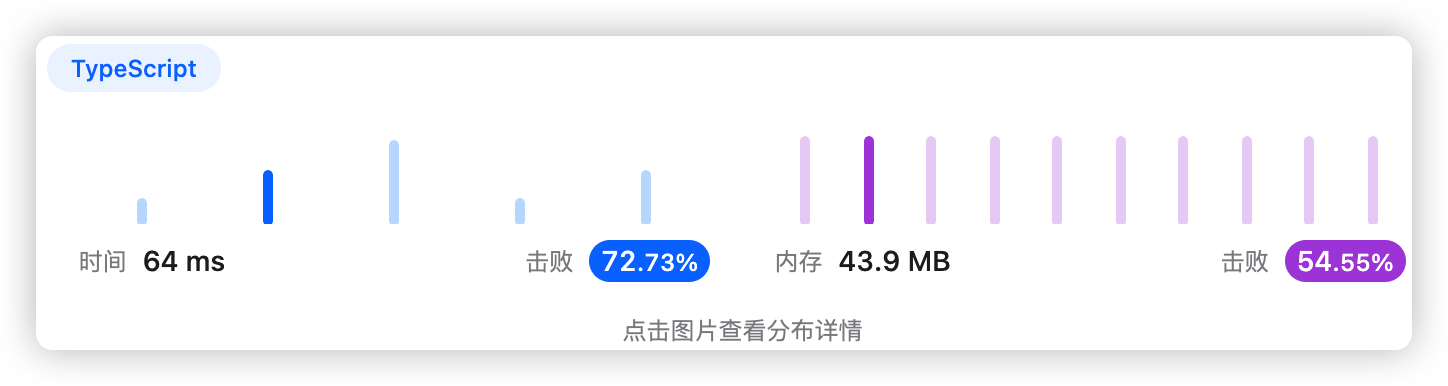
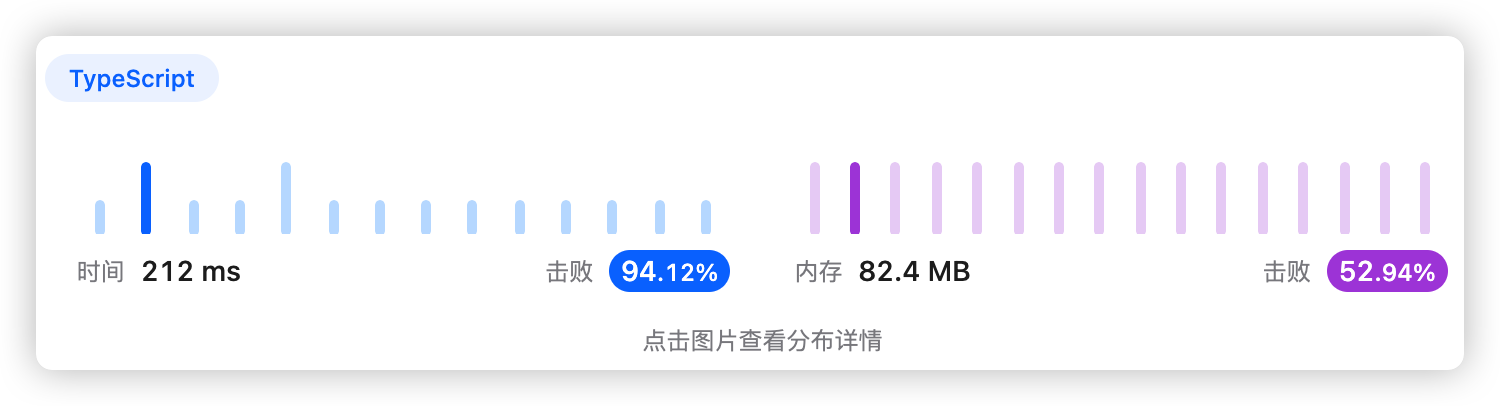
5、执行结果
6、思路2-哈希
将 folder 数组中所有文件夹存入哈希集合 set,遍历检查文件夹 folder[i] 所有前缀路径,若前缀路径存在于 set 中,则说明 folder[i] 是子文件夹
7、代码
function removeSubfolders(folder: string[]): string[] {
const ans = [], set = new Set(folder);
for (const f of folder) {
let found = false;
for (let i = 0; i < f.length;) {
i = f.indexOf('/', i + 1);
if (i < 0) break;
const dir = f.slice(0, i);
if (set.has(dir)) {
found = true;
break;
}
}
if (!found) ans.push(f);
}
return ans;
};
8、复杂度
- 时间复杂度:
- 空间复杂度:
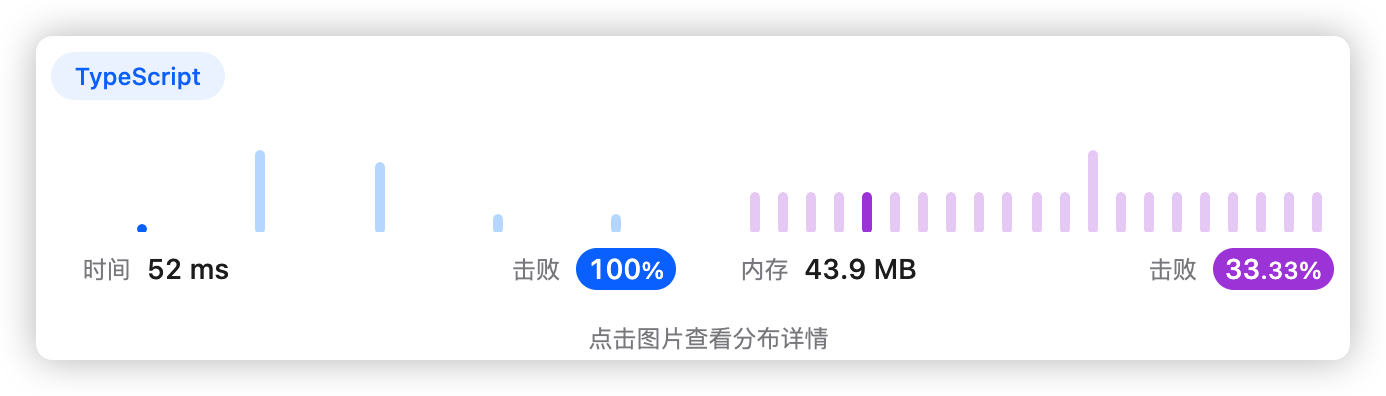
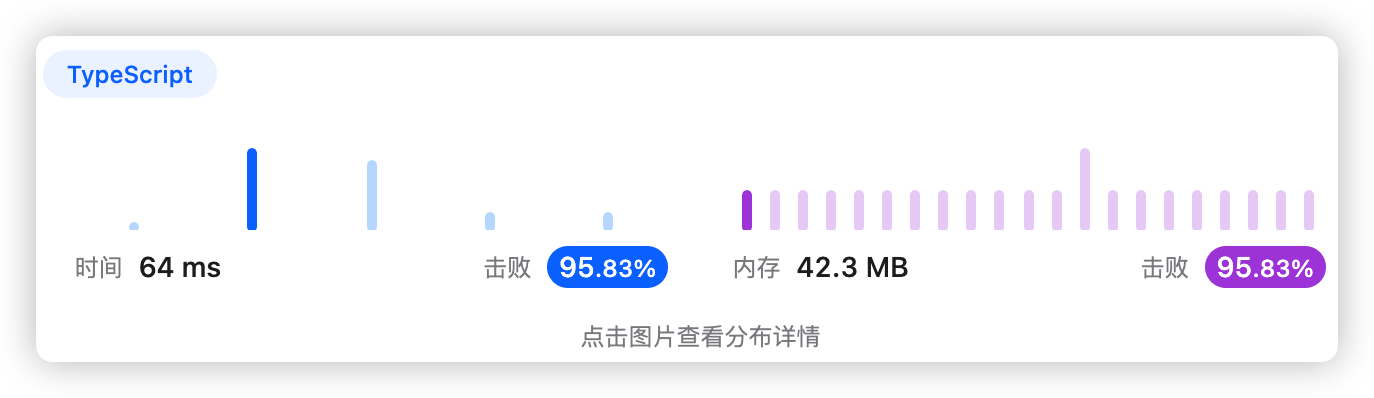
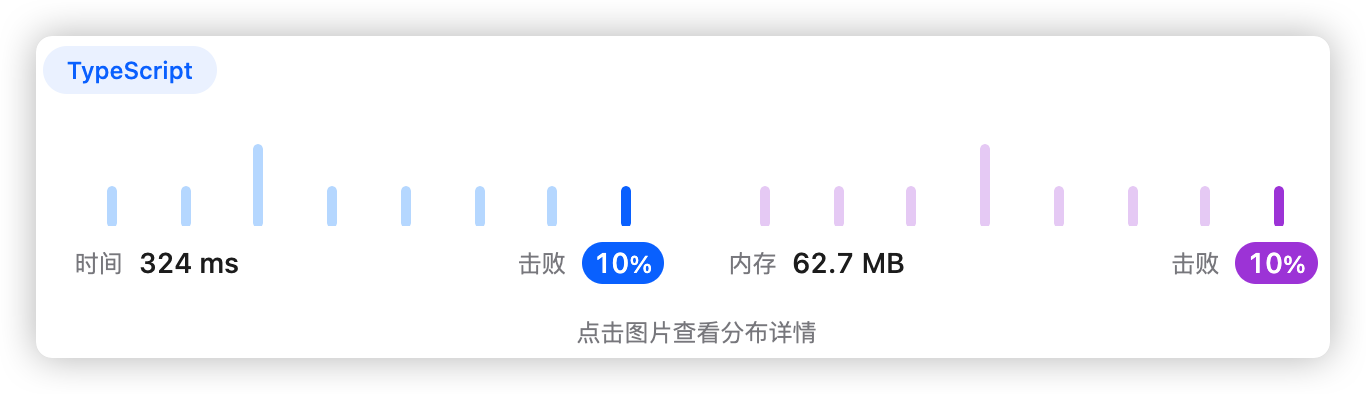
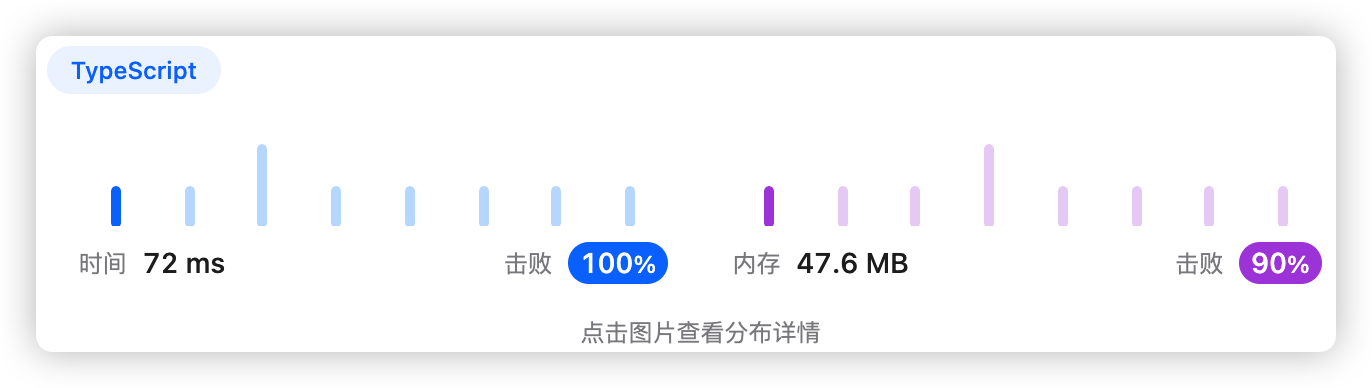
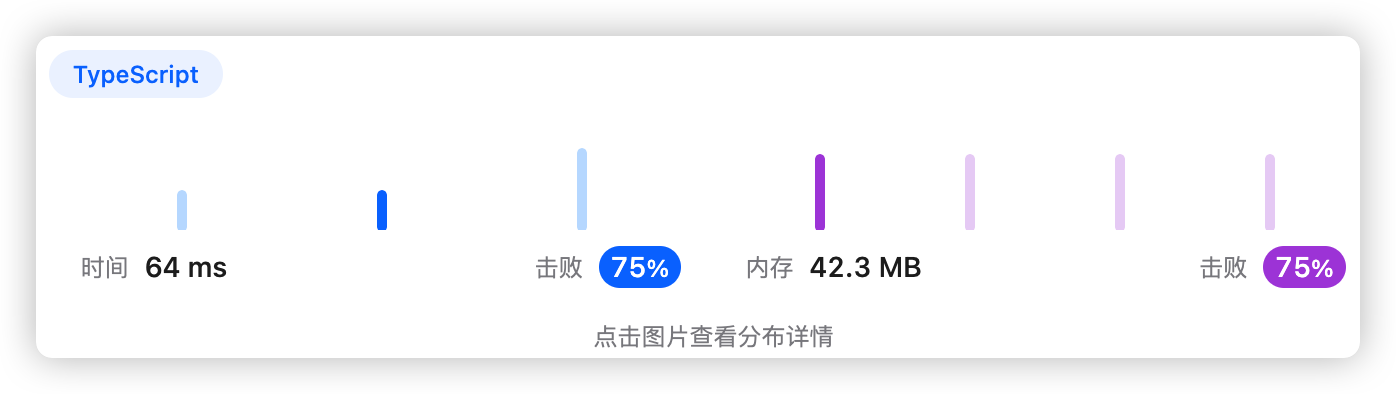
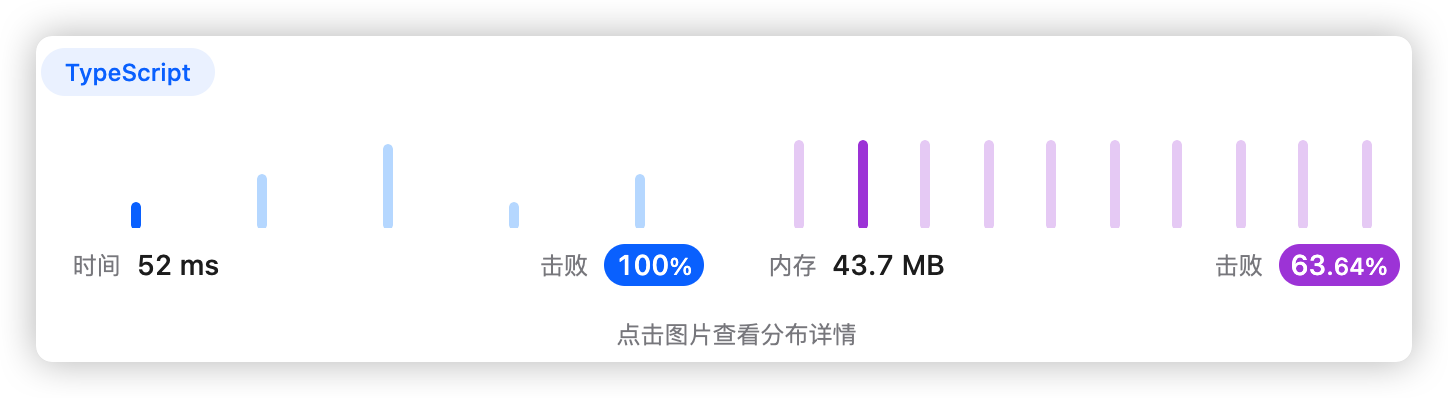
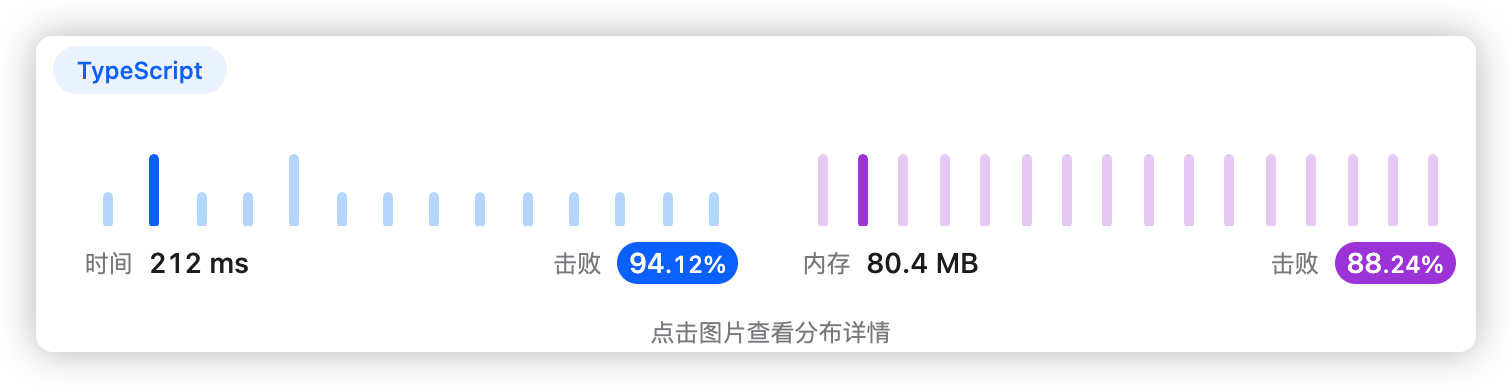
9、执行结果