1、题干
给你一个整数数组 nums ,返回 nums[i] XOR nums[j] 的最大运算结果,其中 0 ≤ i ≤ j < n 。
示例 1:
输入:nums = [3,10,5,25,2,8]
输出:28
解释:最大运算结果是 5 XOR 25 = 28.示例 2:
输入:nums = [14,70,53,83,49,91,36,80,92,51,66,70]
输出:127
提示:
1 <= nums.length <= 2 * 1050 <= nums[i] <= 231 - 1
注意:本题与主站 421 题相同: https://leetcode-cn.com/problems/maximum-xor-of-two-numbers-in-an-array/
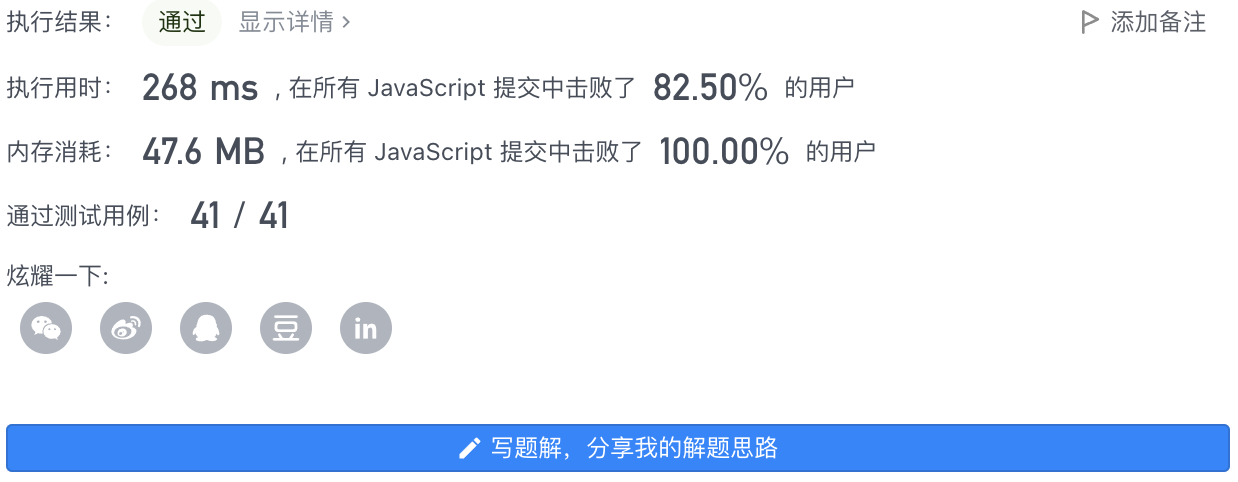
题目比较难,没能想到官解那些优秀解法,尝试了暴力解法并两次剪枝优化后,不仅AC还超过82%提交
2、解题思路
解题关键是:最大异或结果一定是由 二进制位数最多的一个数 与 另一个数 进行异或运算得来。
以 [3,10,5,25,2,8] 为例,用二进制表示是:[11, 1010, 101, 11001, 10, 1000],其中 二进制位数最多 的只有1个数 25(11001),接着计算 25 跟其他数的异或结果并取最大值即可。
暴力解法步骤 :
- 先对数组进行降序排序
- 对所有数进行异或运算并取最大值
剪枝优化:
- 优化1:异或结果的最大可能是:二进制位数最多的数异或之后所有二进制位变成 1,假设为
MAX_NUM。如果运算结果已达到最大可能MAX_NUM,则直接退出程序。(效果显著) - 优化2:异或运算时,第一个数取 二进制位数最多的数 ,第二个数取 二进制位数更少的数 。第一个数不变的情况下,第二个数的二进制位数与其相同则异或会导致最高位变为 0,结果必然小于第二个数的二进制位数更少的情况。
3、代码
// 优化1
var findMaximumXOR = function (nums) {
nums.sort((a, b) => b - a);
const c = Math.log2(nums[0]) >> 0;
let idx = nums.findIndex((n) => n < 1 << c);
if (idx < 0) idx = nums.length;
const MAX_NUM = (1 << (c + 1)) - 1;
let res = 0;
for (let i = 0; i < idx; i++) {
for (let j = i + 1; j < nums.length; j++) {
res = Math.max(res, nums[i] ^ nums[j]);
if (res === MAX_NUM) return res;
}
}
return res;
};
// 优化1 + 优化2
var findMaximumXOR = function (nums) {
nums.sort((a, b) => b - a);
const c = Math.log2(nums[0]) >> 0;
const idx = nums.findIndex((n) => n < 1 << c);
const MAX_NUM = (1 << (c + 1)) - 1;
let res = 0;
if (idx > -1) {
for (let i = 0; i < idx; i++) {
for (let j = idx; j < nums.length; j++) {
res = Math.max(res, nums[i] ^ nums[j]);
if (res === MAX_NUM) return res;
}
}
} else {
for (let i = 0; i < nums.length; i++) {
for (let j = i + 1; j < nums.length; j++) res = Math.max(res, nums[i] ^ nums[j]);
}
}
return res;
};
4、复杂度
- 时间复杂度:
- 空间复杂度:
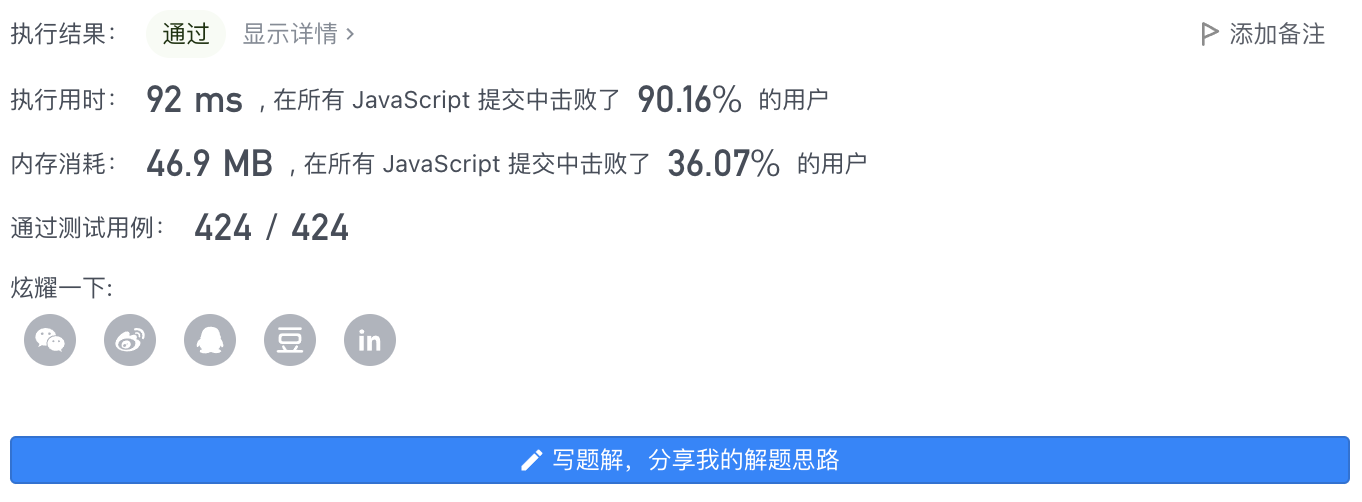
5、执行结果