1、题干
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
回文字符串 是正着读和倒过来读一样的字符串。
子字符串 是字符串中的由连续字符组成的一个序列。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例 1:
输入:s = "abc"
输出:3
解释:三个回文子串: "a", "b", "c"
示例 2:
输入:s = "aaa"
输出:6
解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
提示:
1 <= s.length <= 1000s由小写英文字母组成
2、解法1-暴力解法
双指针 i 和 j 枚举所有子串的起点和终点,遍历 i 和 j 区间段内的字符判断其是否回文。
这种方式时间复杂度是 ,复杂度太高,如果数据量再大点可能会超时。其中双指针枚举的时间复杂度是 ,回文判断的时间复杂度是 。解法2就是在此基础上优化了回文判断的复杂度。
3、代码
var countSubstrings = function (s) {
function isPal(s, l, r) {
for (let i = l; i < (l + r) / 2; i++) {
if (s[i] !== s[l + r - i - 1]) return false;
}
return true
}
let count = 0;
for (let i = 0; i < s.length; i++) {
for (let j = i + 1; j <= s.length; j++) {
if (isPal(s, i, j)) count++;
}
}
return count;
};
4、复杂度
- 时间复杂度:
- 空间复杂度:
5、执行结果
- 执行用时: 308 ms
- 内存消耗: 38.4 MB
6、解法2-双指针
该解法是解法1的优化版本。先使用双指针 i 和 j 枚举所有子串的起点和终点,同时分别按顺序和逆序累加所有遍历过的字符得到字符串 s1 和 s2,判断是否回文只需对 s1 和 s2 判等即可。这里将回文判断的时间复杂度从 优化到 ,但整体空间复杂度从 升到 ,算是空间换时间。
7、代码
var countSubstrings = function (s) {
let count = 0;
for (let i = 0; i < s.length; i++) {
let s1 = '', s2 = '';
for (let j = i; j < s.length; j++) {
s1 += s[j], s2 = s[j] + s2;
if (s1 === s2) count++;
}
}
return count;
};
8、复杂度
- 时间复杂度:
- 空间复杂度:
9、执行结果
- 执行用时: 196 ms
- 内存消耗: 44.3 MB
这里的执行用时仍然比较高,是因为字符串拼接属于耗时操作。
10、解法3-中心扩展
枚举所有可能的回文中心 s[i] 或 s[i]、s[i + 1],若回文子串长度为奇数则其中心为 s[i],回文子串长度为偶数则其中心为 s[i]、s[i + 1];以中心向左右两边扩展,即左边界 l 减一右边界 r 加1,如果 s[l] 与 s[r] 相等则回文数加1。
11、代码
var countSubstrings = function (s) {
let count = 0;
for (let i = 0; i < s.length; i++) {
for (let l = i, r = i; l >= 0 && s[l] === s[r]; l--, r++) count++;
for (let l = i, r = i + 1; l >= 0 && s[l] === s[r]; l--, r++) count++;
}
return count;
};
12、复杂度
- 时间复杂度:
- 空间复杂度:
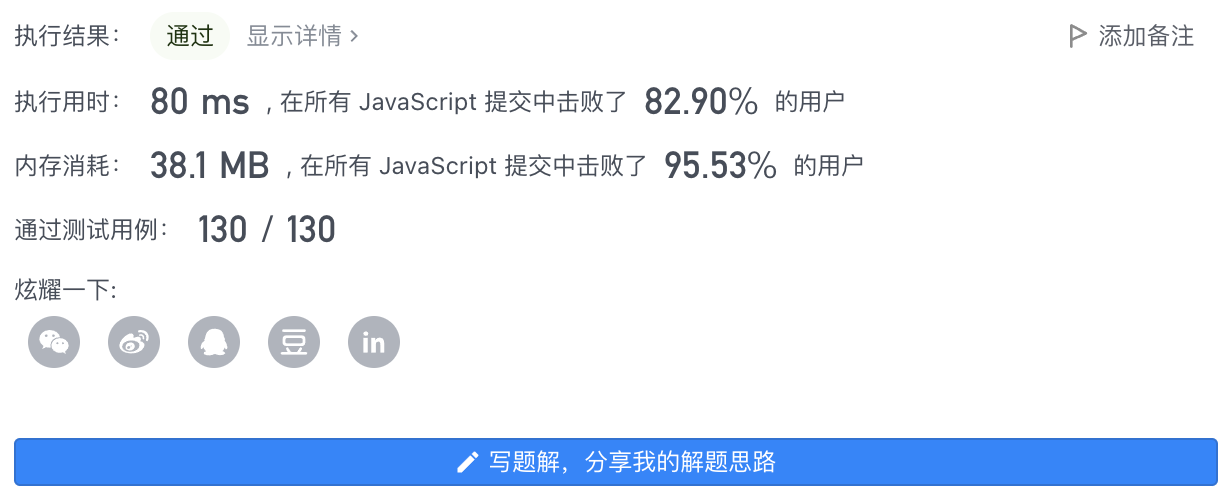
13、执行结果