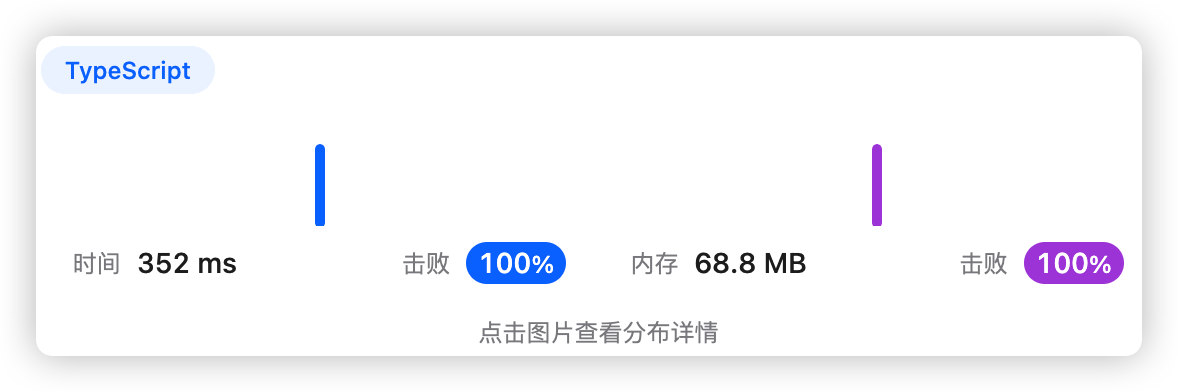
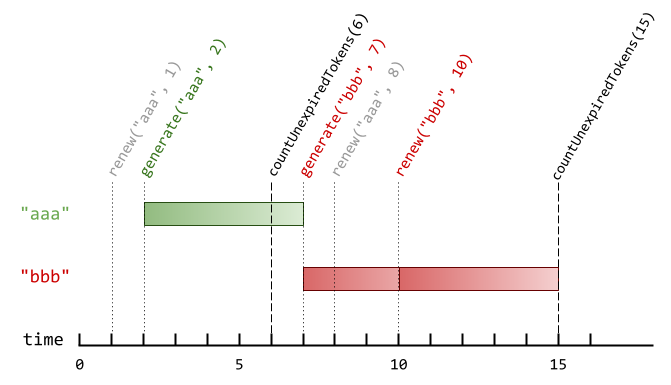
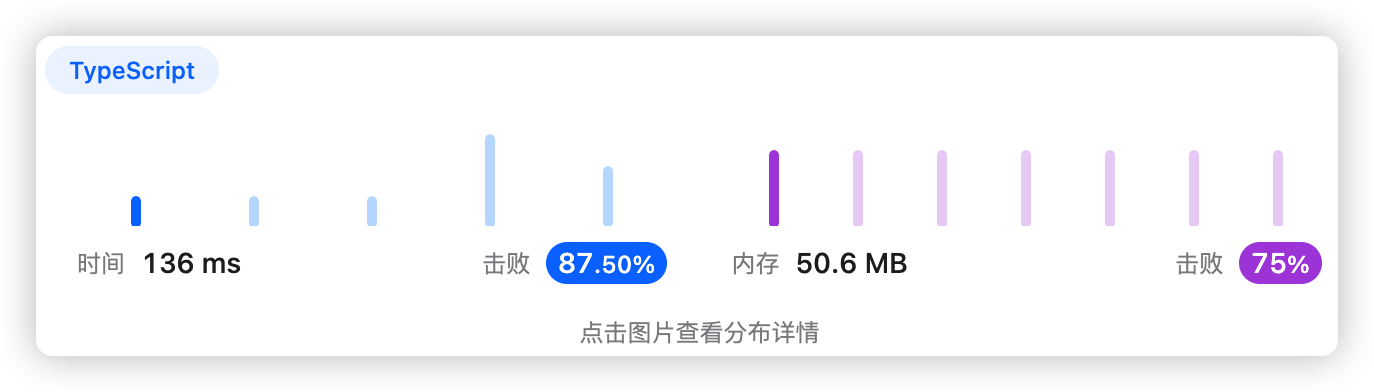
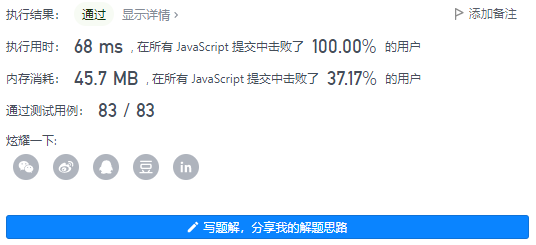
var MKAverage = function (m, k) {
this.m = m;
this.k = k;
this.nums = [];
this.trees = [new AVLTree(), new AVLTree(), new AVLTree()];
this.sum = 0;
};
MKAverage.prototype.addElement = function (num) {
this.nums.push(num);
const trees = this.trees;
if (this.nums.length > this.m) {
const n = this.nums[this.nums.length - this.m - 1];
let i = trees.findIndex(t => t.contains(n));
if (i === 1) this.sum -= n;
trees[i].remove(n);
for (; i < trees.length - 1 && trees[i + 1].size > 0; i++) {
const tmin = trees[i + 1].min();
trees[i + 1].remove(tmin);
trees[i].insert(tmin);
if (i === 0) this.sum -= tmin;
else if (i === 1) this.sum += tmin;
}
}
for (let i = 0; i < trees.length; i++) {
const c = i !== 1 ? this.k : this.m - 2 * this.k;
trees[i].insert(num);
if (i === 1) this.sum += num;
if (trees[i].size <= c) break;
num = trees[i].max();
trees[i].remove(num);
if (i === 1) this.sum -= num;
}
};
MKAverage.prototype.calculateMKAverage = function () {
return this.nums.length < this.m ? -1 : (this.sum / (this.m - 2 * this.k)) >> 0;
};
function print(root,printNode){if(printNode===void 0)printNode=function(n){return n.key};var out=[];row(root,'',true,function(v){return out.push(v)},printNode);return out.join('')}function row(root,prefix,isTail,out,printNode){if(root){out((""+prefix+(isTail?'└── ':'├── ')+(printNode(root))+"\n"));var indent=prefix+(isTail?' ':'│ ');if(root.left){row(root.left,indent,false,out,printNode)}if(root.right){row(root.right,indent,true,out,printNode)}}}function isBalanced(root){if(root===null){return true}var lh=height(root.left);var rh=height(root.right);if(Math.abs(lh-rh)<=1&&isBalanced(root.left)&&isBalanced(root.right)){return true}return false}function height(node){return node?(1+Math.max(height(node.left),height(node.right))):0}function loadRecursive(parent,keys,values,start,end){var size=end-start;if(size>0){var middle=start+Math.floor(size/2);var key=keys[middle];var data=values[middle];var node={key:key,data:data,parent:parent};node.left=loadRecursive(node,keys,values,start,middle);node.right=loadRecursive(node,keys,values,middle+1,end);return node}return null}function markBalance(node){if(node===null){return 0}var lh=markBalance(node.left);var rh=markBalance(node.right);node.balanceFactor=lh-rh;return Math.max(lh,rh)+1}function sort(keys,values,left,right,compare){if(left>=right){return}var pivot=keys[(left+right)>>1];var i=left-1;var j=right+1;while(true){do{i++}while(compare(keys[i],pivot)<0);do{j--}while(compare(keys[j],pivot)>0);if(i>=j){break}var tmp=keys[i];keys[i]=keys[j];keys[j]=tmp;tmp=values[i];values[i]=values[j];values[j]=tmp}sort(keys,values,left,j,compare);sort(keys,values,j+1,right,compare)}function DEFAULT_COMPARE(a,b){return a>b?1:a<b?-1:0}function rotateLeft(node){var rightNode=node.right;node.right=rightNode.left;if(rightNode.left){rightNode.left.parent=node}rightNode.parent=node.parent;if(rightNode.parent){if(rightNode.parent.left===node){rightNode.parent.left=rightNode}else{rightNode.parent.right=rightNode}}node.parent=rightNode;rightNode.left=node;node.balanceFactor+=1;if(rightNode.balanceFactor<0){node.balanceFactor-=rightNode.balanceFactor}rightNode.balanceFactor+=1;if(node.balanceFactor>0){rightNode.balanceFactor+=node.balanceFactor}return rightNode}function rotateRight(node){var leftNode=node.left;node.left=leftNode.right;if(node.left){node.left.parent=node}leftNode.parent=node.parent;if(leftNode.parent){if(leftNode.parent.left===node){leftNode.parent.left=leftNode}else{leftNode.parent.right=leftNode}}node.parent=leftNode;leftNode.right=node;node.balanceFactor-=1;if(leftNode.balanceFactor>0){node.balanceFactor-=leftNode.balanceFactor}leftNode.balanceFactor-=1;if(node.balanceFactor<0){leftNode.balanceFactor+=node.balanceFactor}return leftNode}var AVLTree=function AVLTree(comparator,noDuplicates){if(noDuplicates===void 0)noDuplicates=false;this._comparator=comparator||DEFAULT_COMPARE;this._root=null;this._size=0;this._noDuplicates=!!noDuplicates};var prototypeAccessors={size:{configurable:true}};AVLTree.prototype.destroy=function destroy(){return this.clear()};AVLTree.prototype.clear=function clear(){this._root=null;this._size=0;return this};prototypeAccessors.size.get=function(){return this._size};AVLTree.prototype.contains=function contains(key){if(this._root){var node=this._root;var comparator=this._comparator;while(node){var cmp=comparator(key,node.key);if(cmp===0){return true}else if(cmp<0){node=node.left}else{node=node.right}}}return false};AVLTree.prototype.next=function next(node){var successor=node;if(successor){if(successor.right){successor=successor.right;while(successor.left){successor=successor.left}}else{successor=node.parent;while(successor&&successor.right===node){node=successor;successor=successor.parent}}}return successor};AVLTree.prototype.prev=function prev(node){var predecessor=node;if(predecessor){if(predecessor.left){predecessor=predecessor.left;while(predecessor.right){predecessor=predecessor.right}}else{predecessor=node.parent;while(predecessor&&predecessor.left===node){node=predecessor;predecessor=predecessor.parent}}}return predecessor};AVLTree.prototype.forEach=function forEach(callback){var current=this._root;var s=[],done=false,i=0;while(!done){if(current){s.push(current);current=current.left}else{if(s.length>0){current=s.pop();callback(current,i++);current=current.right}else{done=true}}}return this};AVLTree.prototype.range=function range(low,high,fn,ctx){var Q=[];var compare=this._comparator;var node=this._root,cmp;while(Q.length!==0||node){if(node){Q.push(node);node=node.left}else{node=Q.pop();cmp=compare(node.key,high);if(cmp>0){break}else if(compare(node.key,low)>=0){if(fn.call(ctx,node)){return this}}node=node.right}}return this};AVLTree.prototype.keys=function keys(){var current=this._root;var s=[],r=[],done=false;while(!done){if(current){s.push(current);current=current.left}else{if(s.length>0){current=s.pop();r.push(current.key);current=current.right}else{done=true}}}return r};AVLTree.prototype.values=function values(){var current=this._root;var s=[],r=[],done=false;while(!done){if(current){s.push(current);current=current.left}else{if(s.length>0){current=s.pop();r.push(current.data);current=current.right}else{done=true}}}return r};AVLTree.prototype.at=function at(index){var current=this._root;var s=[],done=false,i=0;while(!done){if(current){s.push(current);current=current.left}else{if(s.length>0){current=s.pop();if(i===index){return current}i++;current=current.right}else{done=true}}}return null};AVLTree.prototype.minNode=function minNode(){var node=this._root;if(!node){return null}while(node.left){node=node.left}return node};AVLTree.prototype.maxNode=function maxNode(){var node=this._root;if(!node){return null}while(node.right){node=node.right}return node};AVLTree.prototype.min=function min(){var node=this._root;if(!node){return null}while(node.left){node=node.left}return node.key};AVLTree.prototype.max=function max(){var node=this._root;if(!node){return null}while(node.right){node=node.right}return node.key};AVLTree.prototype.isEmpty=function isEmpty(){return!this._root};AVLTree.prototype.pop=function pop(){var node=this._root,returnValue=null;if(node){while(node.left){node=node.left}returnValue={key:node.key,data:node.data};this.remove(node.key)}return returnValue};AVLTree.prototype.popMax=function popMax(){var node=this._root,returnValue=null;if(node){while(node.right){node=node.right}returnValue={key:node.key,data:node.data};this.remove(node.key)}return returnValue};AVLTree.prototype.find=function find(key){var root=this._root;var subtree=root,cmp;var compare=this._comparator;while(subtree){cmp=compare(key,subtree.key);if(cmp===0){return subtree}else if(cmp<0){subtree=subtree.left}else{subtree=subtree.right}}return null};AVLTree.prototype.insert=function insert(key,data){if(!this._root){this._root={parent:null,left:null,right:null,balanceFactor:0,key:key,data:data};this._size++;return this._root}var compare=this._comparator;var node=this._root;var parent=null;var cmp=0;if(this._noDuplicates){while(node){cmp=compare(key,node.key);parent=node;if(cmp===0){return null}else if(cmp<0){node=node.left}else{node=node.right}}}else{while(node){cmp=compare(key,node.key);parent=node;if(cmp<=0){node=node.left}else{node=node.right}}}var newNode={left:null,right:null,balanceFactor:0,parent:parent,key:key,data:data};var newRoot;if(cmp<=0){parent.left=newNode}else{parent.right=newNode}while(parent){cmp=compare(parent.key,key);if(cmp<0){parent.balanceFactor-=1}else{parent.balanceFactor+=1}if(parent.balanceFactor===0){break}else if(parent.balanceFactor<-1){if(parent.right.balanceFactor===1){rotateRight(parent.right)}newRoot=rotateLeft(parent);if(parent===this._root){this._root=newRoot}break}else if(parent.balanceFactor>1){if(parent.left.balanceFactor===-1){rotateLeft(parent.left)}newRoot=rotateRight(parent);if(parent===this._root){this._root=newRoot}break}parent=parent.parent}this._size++;return newNode};AVLTree.prototype.remove=function remove(key){if(!this._root){return null}var node=this._root;var compare=this._comparator;var cmp=0;while(node){cmp=compare(key,node.key);if(cmp===0){break}else if(cmp<0){node=node.left}else{node=node.right}}if(!node){return null}var returnValue=node.key;var max,min;if(node.left){max=node.left;while(max.left||max.right){while(max.right){max=max.right}node.key=max.key;node.data=max.data;if(max.left){node=max;max=max.left}}node.key=max.key;node.data=max.data;node=max}if(node.right){min=node.right;while(min.left||min.right){while(min.left){min=min.left}node.key=min.key;node.data=min.data;if(min.right){node=min;min=min.right}}node.key=min.key;node.data=min.data;node=min}var parent=node.parent;var pp=node;var newRoot;while(parent){if(parent.left===pp){parent.balanceFactor-=1}else{parent.balanceFactor+=1}if(parent.balanceFactor<-1){if(parent.right.balanceFactor===1){rotateRight(parent.right)}newRoot=rotateLeft(parent);if(parent===this._root){this._root=newRoot}parent=newRoot}else if(parent.balanceFactor>1){if(parent.left.balanceFactor===-1){rotateLeft(parent.left)}newRoot=rotateRight(parent);if(parent===this._root){this._root=newRoot}parent=newRoot}if(parent.balanceFactor===-1||parent.balanceFactor===1){break}pp=parent;parent=parent.parent}if(node.parent){if(node.parent.left===node){node.parent.left=null}else{node.parent.right=null}}if(node===this._root){this._root=null}this._size--;return returnValue};AVLTree.prototype.load=function load(keys,values,presort){if(keys===void 0)keys=[];if(values===void 0)values=[];if(this._size!==0){throw new Error('bulk-load: tree is not empty');}var size=keys.length;if(presort){sort(keys,values,0,size-1,this._comparator)}this._root=loadRecursive(null,keys,values,0,size);markBalance(this._root);this._size=size;return this};AVLTree.prototype.isBalanced=function isBalanced$1(){return isBalanced(this._root)};AVLTree.prototype.toString=function toString(printNode){return print(this._root,printNode)};Object.defineProperties(AVLTree.prototype,prototypeAccessors);