1、题干
设计一个使用单词列表进行初始化的数据结构,单词列表中的单词 互不相同 。 如果给出一个单词,请判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于已构建的神奇字典中。
实现 MagicDictionary 类:
MagicDictionary()初始化对象void buildDict(String[] dictionary)使用字符串数组dictionary设定该数据结构,dictionary中的字符串互不相同bool search(String searchWord)给定一个字符串searchWord,判定能否只将字符串中 一个 字母换成另一个字母,使得所形成的新字符串能够与字典中的任一字符串匹配。如果可以,返回true;否则,返回false。
示例:
输入
inputs = ["MagicDictionary", "buildDict", "search", "search", "search", "search"]
inputs = [[], [["hello", "leetcode"]], ["hello"], ["hhllo"], ["hell"], ["leetcoded"]]
输出
[null, null, false, true, false, false]
解释
MagicDictionary magicDictionary = new MagicDictionary();
magicDictionary.buildDict(["hello", "leetcode"]);
magicDictionary.search("hello"); // 返回 False
magicDictionary.search("hhllo"); // 将第二个 'h' 替换为 'e' 可以匹配 "hello" ,所以返回 True
magicDictionary.search("hell"); // 返回 False
magicDictionary.search("leetcoded"); // 返回 False
提示:
1 <= dictionary.length <= 1001 <= dictionary[i].length <= 100dictionary[i]仅由小写英文字母组成dictionary中的所有字符串 互不相同1 <= searchWord.length <= 100searchWord仅由小写英文字母组成buildDict仅在search之前调用一次- 最多调用
100次search
注意:本题与主站 676 题相同: https://leetcode-cn.com/problems/implement-magic-dictionary/
2、解法1-字符串比较
数组存储字典,查找时直接进行字符串比较,如果不匹配的字符数量为1返回true,否则继续查找直至结束返回false
3、代码
var MagicDictionary = function () {
this.dict = [];
};
MagicDictionary.prototype.buildDict = function (dictionary) {
this.dict = dictionary;
};
MagicDictionary.prototype.search = function (searchWord) {
for (let i = 0; i < this.dict.length; i++) {
if (searchWord.length !== this.dict[i].length) continue;
let diff = 0;
for (let j = 0; j < searchWord.length; j++) {
if (diff > 1) break;
if (searchWord[j] !== this.dict[i][j]) diff++;
}
if (diff === 1) return true;
}
return false;
};
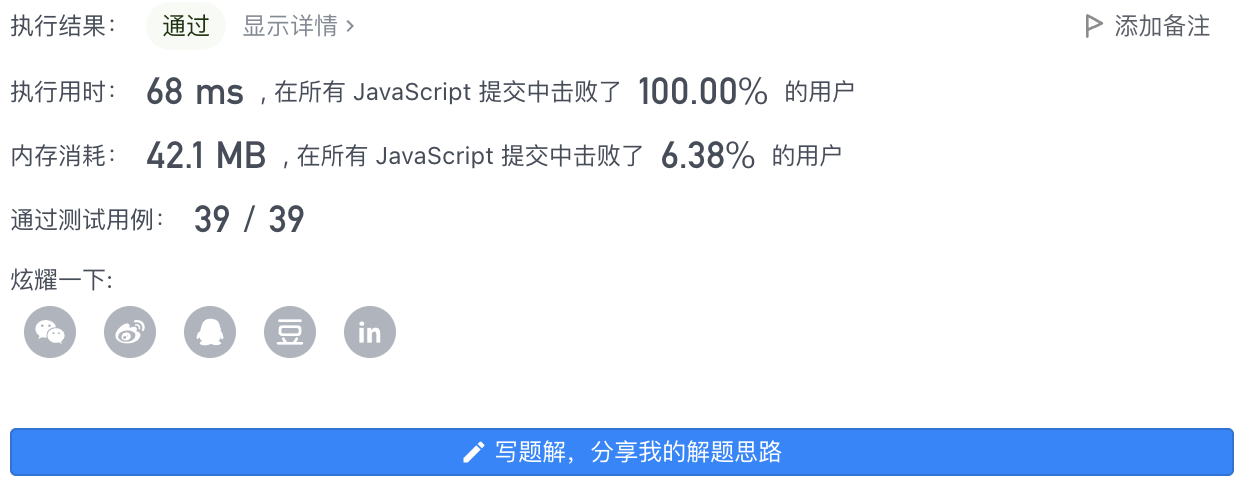
4、执行结果
5、解法2-哈希表
哈希表存储字典,查找时对源字符串的每一位做替换,若替换后哈希表存在该字符串则返回true,否则继续查找直至结束返回false
6、代码
var MagicDictionary = function () {
this.dict = new Set();
};
MagicDictionary.prototype.buildDict = function (dictionary) {
for (const w of dictionary) this.dict.add(w);
};
MagicDictionary.prototype.search = function (searchWord) {
for (let i = 0; i < searchWord.length; i++) {
const pre = searchWord.slice(0, i), post = searchWord.slice(i + 1);
for (let j = 97; j < 123; j++) {
const c = String.fromCharCode(j);
if (c === searchWord[i]) continue;
if (this.dict.has(pre + c + post)) return true;
}
}
return false;
};
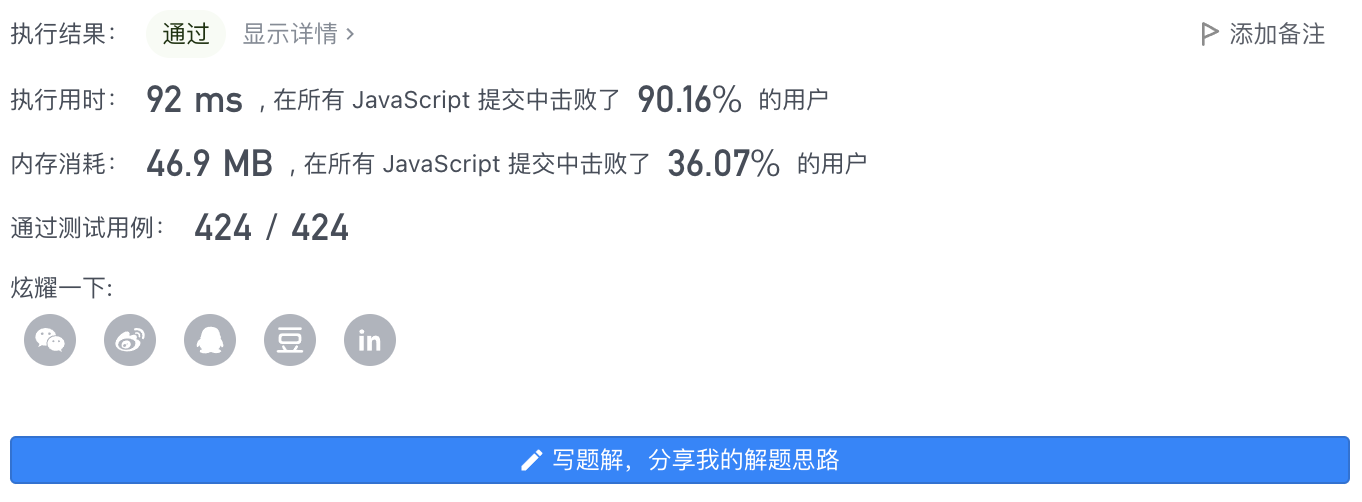
7、执行结果
- 执行用时: 860 ms
- 内存消耗: 48.3 MB