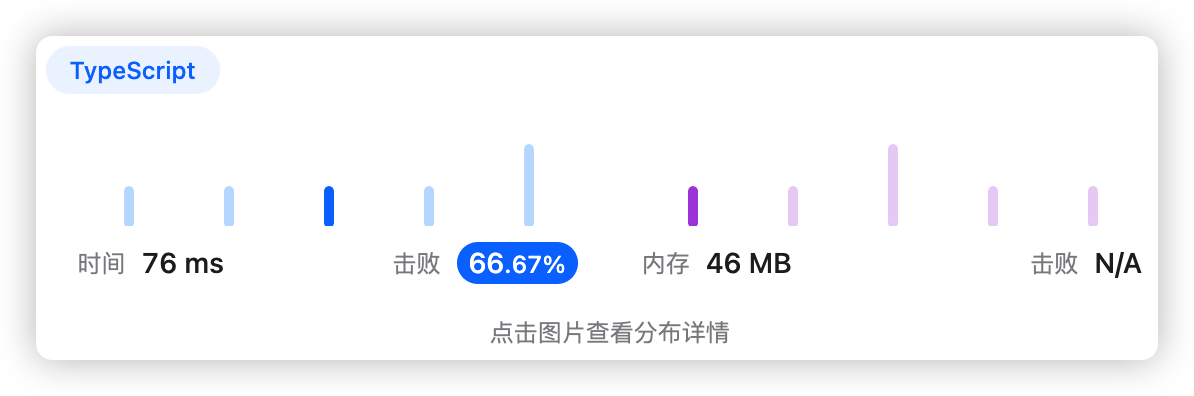
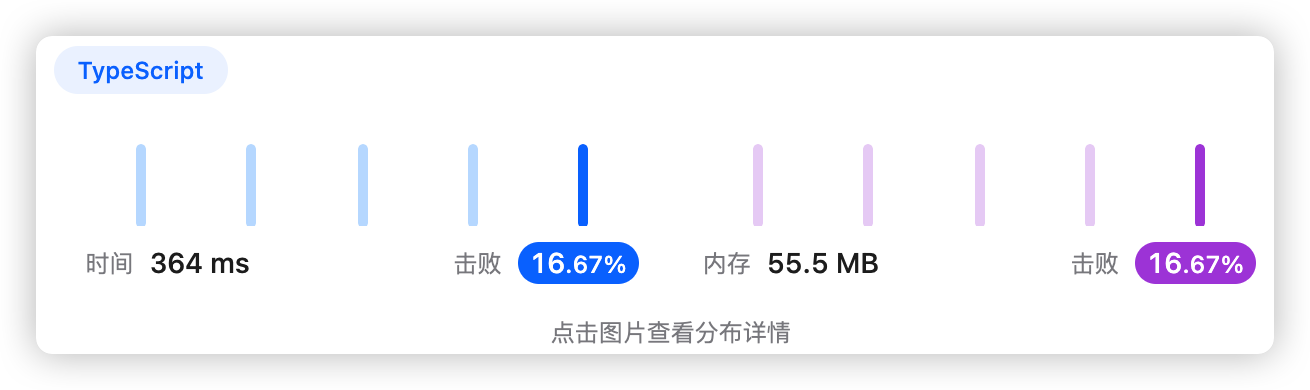
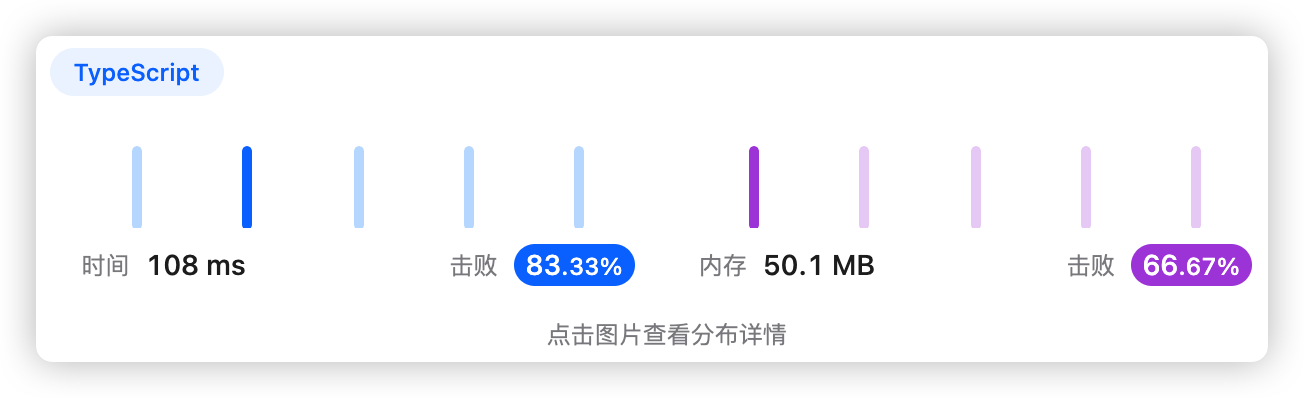
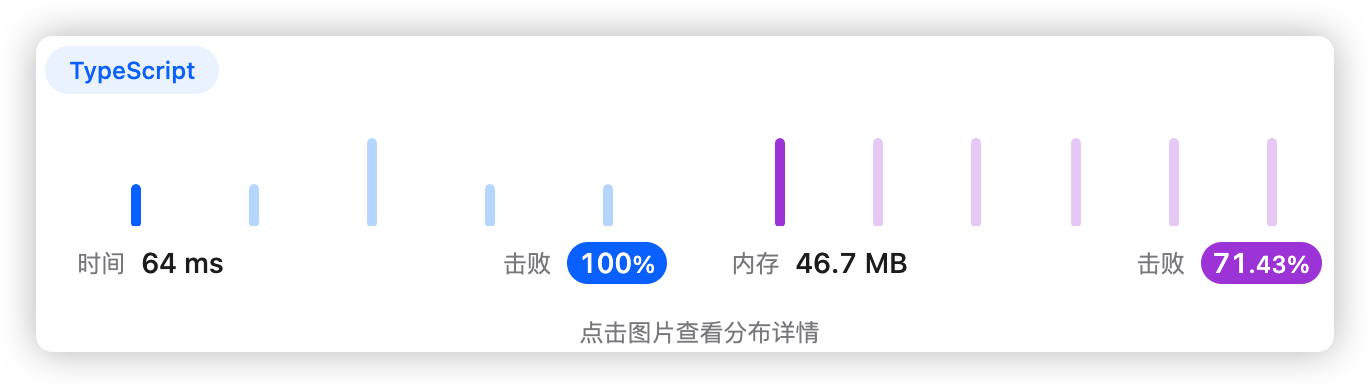
1、题干
给你一个下标从 0 开始的整数数组 nums ,如果满足下述条件,则认为数组 nums 是一个 美丽数组 :
nums.length为偶数- 对所有满足
i % 2 == 0的下标i,nums[i] != nums[i + 1]均成立
注意,空数组同样认为是美丽数组。
你可以从 nums 中删除任意数量的元素。当你删除一个元素时,被删除元素右侧的所有元素将会向左移动一个单位以填补空缺,而左侧的元素将会保持 不变 。
返回使 nums 变为美丽数组所需删除的 最少 元素数目。
示例 1:
输入:nums = [1,1,2,3,5]
输出:1
解释:可以删除 nums[0] 或 nums[1] ,这样得到的 nums = [1,2,3,5] 是一个美丽数组。可以证明,要想使 nums 变为美丽数组,至少需要删除 1 个元素。示例 2:
输入:nums = [1,1,2,2,3,3]
输出:2
解释:可以删除 nums[0] 和 nums[5] ,这样得到的 nums = [1,2,2,3] 是一个美丽数组。可以证明,要想使 nums 变为美丽数组,至少需要删除 2 个元素。
提示:
1 <= nums.length <= 1050 <= nums[i] <= 105
2、思路
模拟一遍删除过程就能过。其他题解说是贪心,也有证明过程,看完还是不懂不理解。这题证明比AC难得多。
3、代码
function minDeletion(nums: number[]): number {
let cur = -Infinity, size = 0;
for (const k of nums) {
if (size % 2 === 0 || k !== cur) cur = k, size++;
}
return nums.length - size + (size % 2);
};