1、题干
如果字符串满足以下条件之一,则可以称之为 有效括号字符串(valid parentheses string,可以简写为 VPS):
- 字符串是一个空字符串
"",或者是一个不为"("或")"的单字符。 - 字符串可以写为
AB(A与B字符串连接),其中A和B都是 有效括号字符串 。 - 字符串可以写为
(A),其中A是一个 有效括号字符串 。
类似地,可以定义任何有效括号字符串 S 的 嵌套深度 depth(S):
depth("") = 0depth(C) = 0,其中C是单个字符的字符串,且该字符不是"("或者")"depth(A + B) = max(depth(A), depth(B)),其中A和B都是 有效括号字符串depth("(" + A + ")") = 1 + depth(A),其中A是一个 有效括号字符串
例如:""、"()()"、"()(()())" 都是 有效括号字符串(嵌套深度分别为 0、1、2),而 ")(" 、"(()" 都不是 有效括号字符串 。
给你一个 有效括号字符串 s,返回该字符串的 s 嵌套深度 。
示例 1:
输入:s = "(1+(2*3)+((8)/4))+1"
输出:3
解释:数字 8 在嵌套的 3 层括号中。
示例 2:
输入:s = "(1)+((2))+(((3)))"
输出:3
提示:
1 <= s.length <= 100s由数字0-9和字符'+'、'-'、'*'、'/'、'('、')'组成- 题目数据保证括号表达式
s是 有效的括号表达式
2、解题思路
根据题意统计左括号数量sum和最大值max,遇到左括号(数量sum加1并更新最大值max,遇到右括号)数量sum减1,最后返回最大值max。
3、代码
var maxDepth = function (s) {
let sum = 0, max = 0;
for (const c of s) {
if (c === '(') max = Math.max(++sum, max);
else if (c === ')') --sum;
}
return max;
};
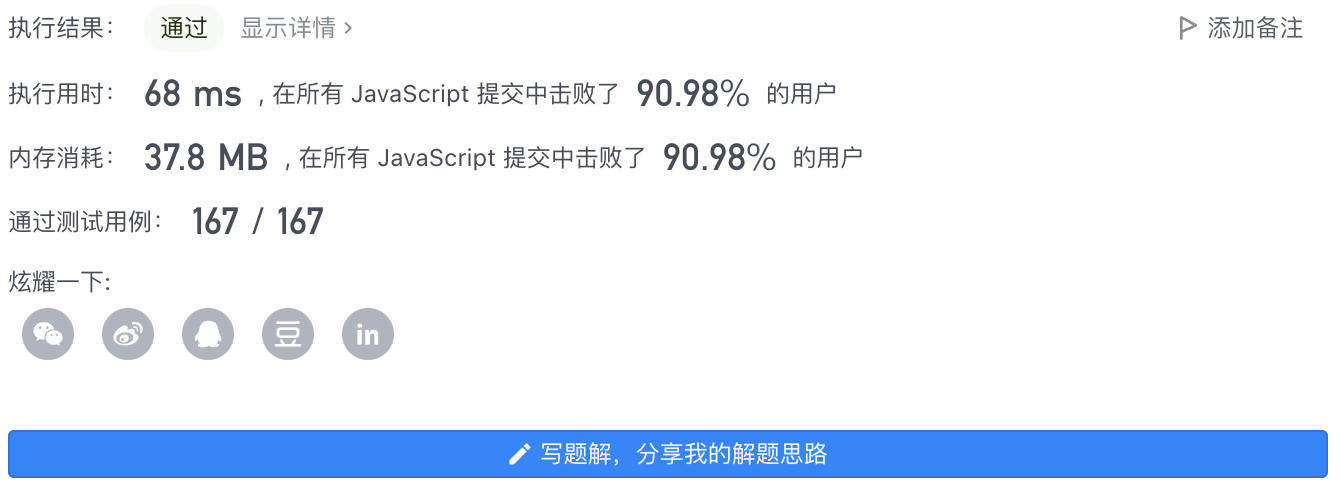
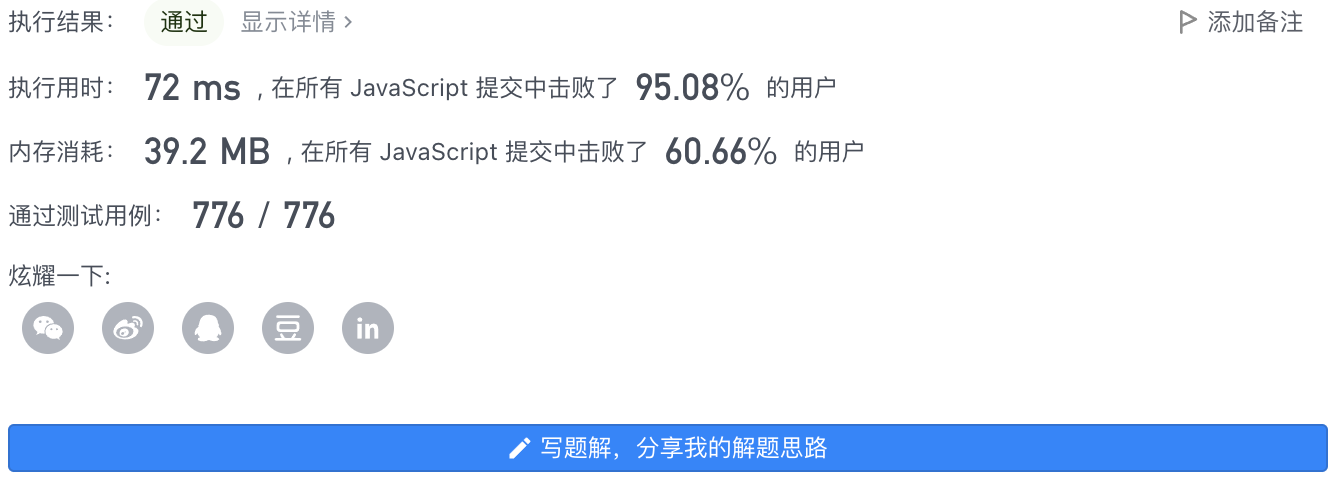
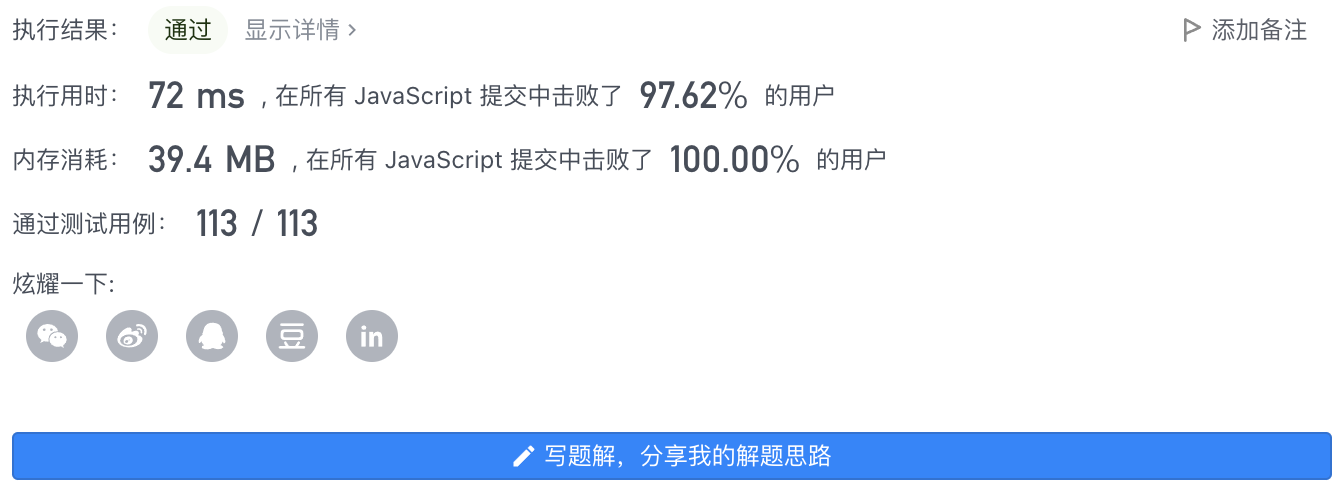
4、执行结果
执行用时: 72 ms 内存消耗: 39 MB
5、整活
用数组的reduce函数遍历字符串,把代码缩减成1行,空间和时间也都有所减少,突然觉得自己又行了😏。
但是,实际项目不推荐这么写,一般情况下写代码更应该重视可维护性。试想这样一行代码过两天自己都看不懂,接手的人心理活动又会是什么样😂。
6、代码
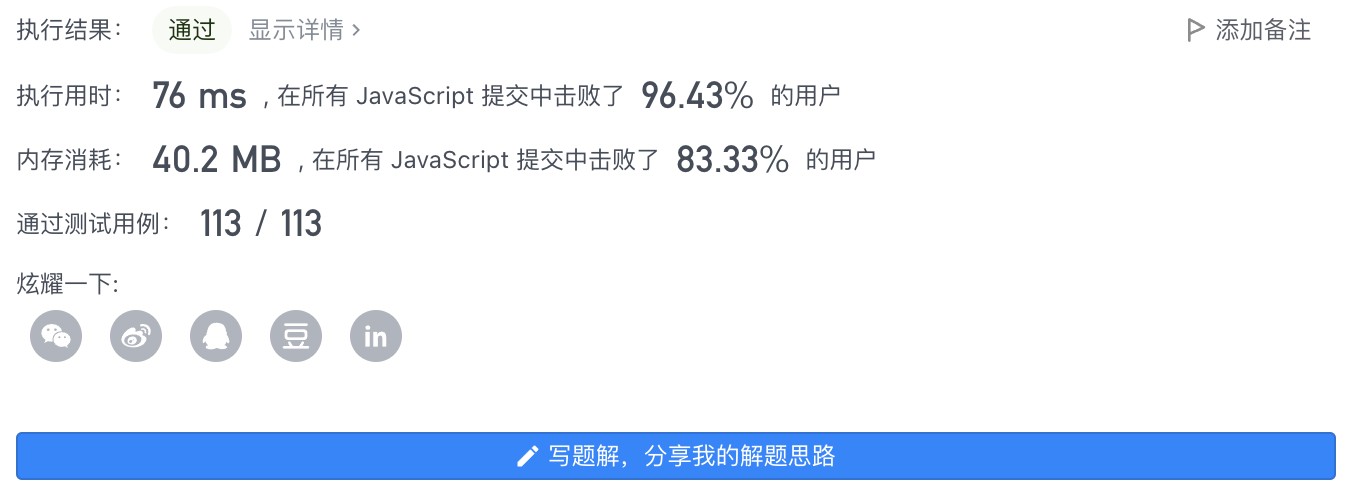
var maxDepth = s => [].reduce.call(s, (a, c) => (c === '(' ? ++a[0] > a[1] && (a[1] = a[0]) : c === ')' && --a[0], a), [0, 0])[1];
7、执行结果