1、题干
当一个字符串 s 包含的每一种字母的大写和小写形式 同时 出现在 s 中,就称这个字符串 s 是 美好 字符串。比方说,"abABB" 是美好字符串,因为 'A' 和 'a' 同时出现了,且 'B' 和 'b' 也同时出现了。然而,"abA" 不是美好字符串因为 'b' 出现了,而 'B' 没有出现。
给你一个字符串 s ,请你返回 s 最长的 美好子字符串 。如果有多个答案,请你返回 最早 出现的一个。如果不存在美好子字符串,请你返回一个空字符串。
示例 1:
输入:s = "YazaAay"
输出:"aAa"
解释:"aAa" 是一个美好字符串,因为这个子串中仅含一种字母,其小写形式 'a' 和大写形式 'A' 也同时出现了。
"aAa" 是最长的美好子字符串。
示例 2:
输入:s = "Bb"
输出:"Bb"
解释:"Bb" 是美好字符串,因为 'B' 和 'b' 都出现了。整个字符串也是原字符串的子字符串。示例 3:
输入:s = "c"
输出:""
解释:没有美好子字符串。示例 4:
输入:s = "dDzeE"
输出:"dD"
解释:"dD" 和 "eE" 都是最长美好子字符串。
由于有多个美好子字符串,返回 "dD" ,因为它出现得最早。
提示:
1 <= s.length <= 100s只包含大写和小写英文字母。
2、解题思路
由题意可知美好子串中不会单独存在大写或小写字母,因此可以在单独的大写或小写字母处断开字符串,对拆分出来的左右子串进行递归查找,直到子串成为美好子串。
3、代码
var longestNiceSubstring = function (s) {
for (let i = 0; i < s.length; i++) {
const c = s[i].charCodeAt(0) < 91 ? s[i].toLowerCase() : s[i].toUpperCase();
if (s.includes(c)) continue;
const s1 = longestNiceSubstring(s.slice(0, i));
const s2 = longestNiceSubstring(s.slice(i + 1));
return s1.length >= s2.length ? s1 : s2;
}
return s;
};
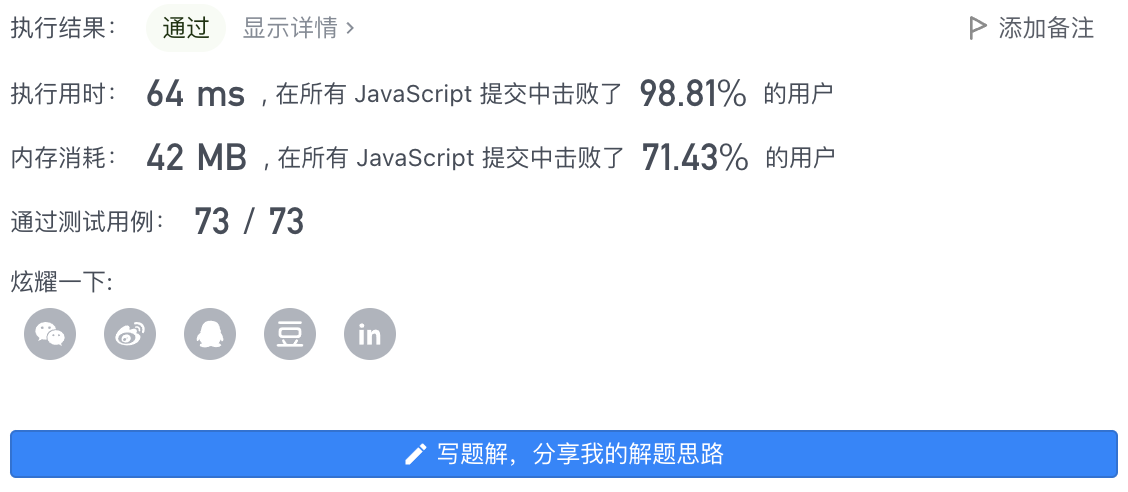
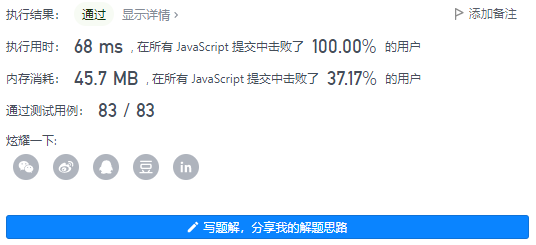
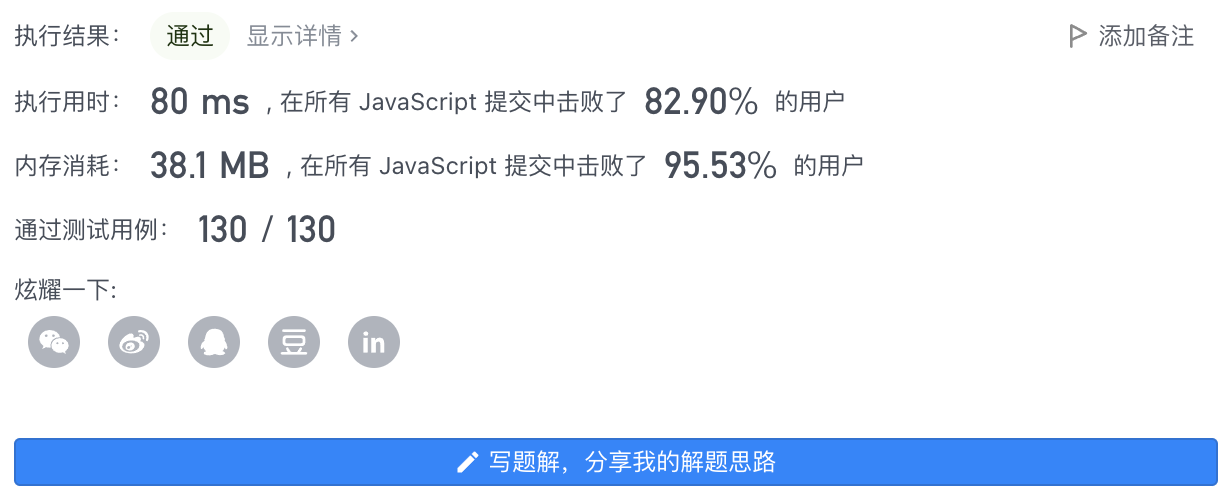
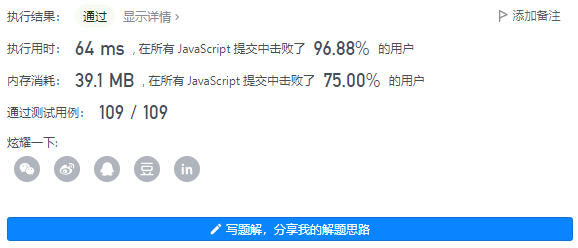
4、执行结果