1、题干
给你一个下标从 0 开始长度为 n 的字符串 num ,它只包含数字。
如果对于 每个 0 <= i < n 的下标 i ,都满足数位 i 在 num 中出现了 num[i]次,那么请你返回 true ,否则返回 false 。
示例 1:
输入:num = "1210"
输出:true
解释:
num[0] = '1' 。数字 0 在 num 中出现了一次。
num[1] = '2' 。数字 1 在 num 中出现了两次。
num[2] = '1' 。数字 2 在 num 中出现了一次。
num[3] = '0' 。数字 3 在 num 中出现了零次。
"1210" 满足题目要求条件,所以返回 true 。
示例 2:
输入:num = "030"
输出:false
解释:
num[0] = '0' 。数字 0 应该出现 0 次,但是在 num 中出现了两次。
num[1] = '3' 。数字 1 应该出现 3 次,但是在 num 中出现了零次。
num[2] = '0' 。数字 2 在 num 中出现了 0 次。
下标 0 和 1 都违反了题目要求,所以返回 false 。
提示:
n == num.length1 <= n <= 10num只包含数字。
2、思路
模拟
3、代码
function digitCount(num: string): boolean {
for (let i = 0; i < 10; i++) {
let c = +num[i] || 0;
for (const n of num) {
if (+n === i) c--;
}
if (c) return false;
}
return true;
};
4、复杂度
- 时间复杂度:
- 空间复杂度:
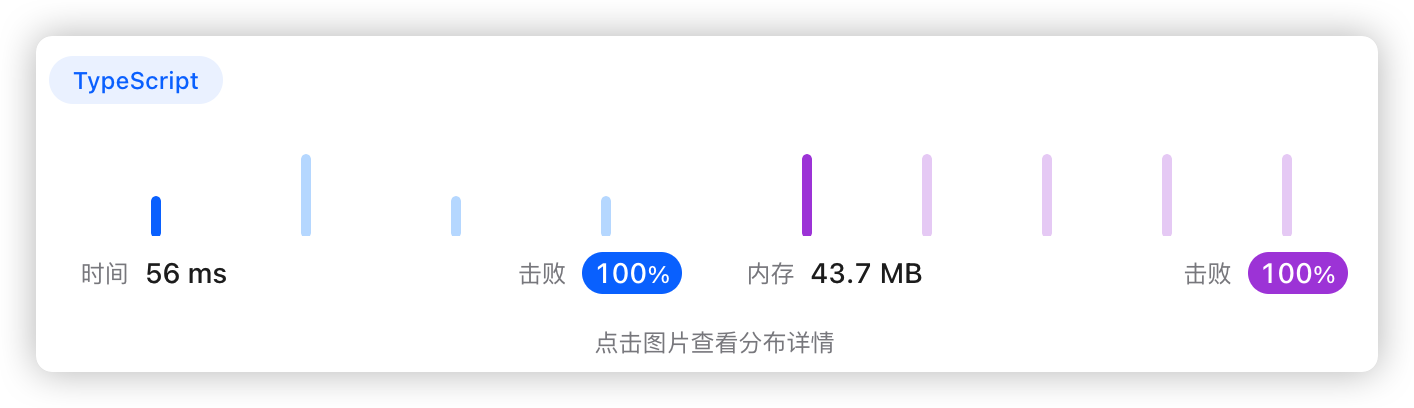
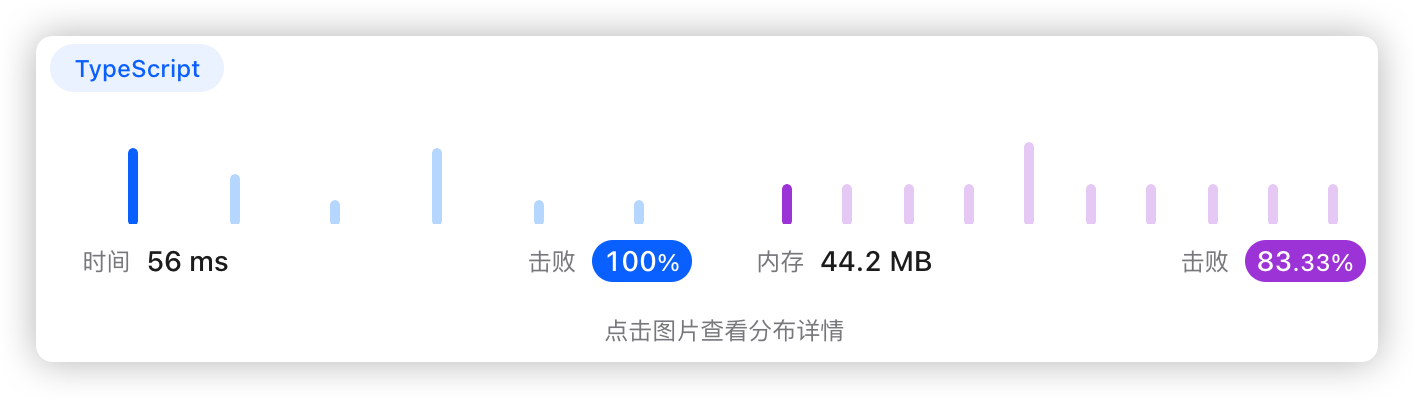
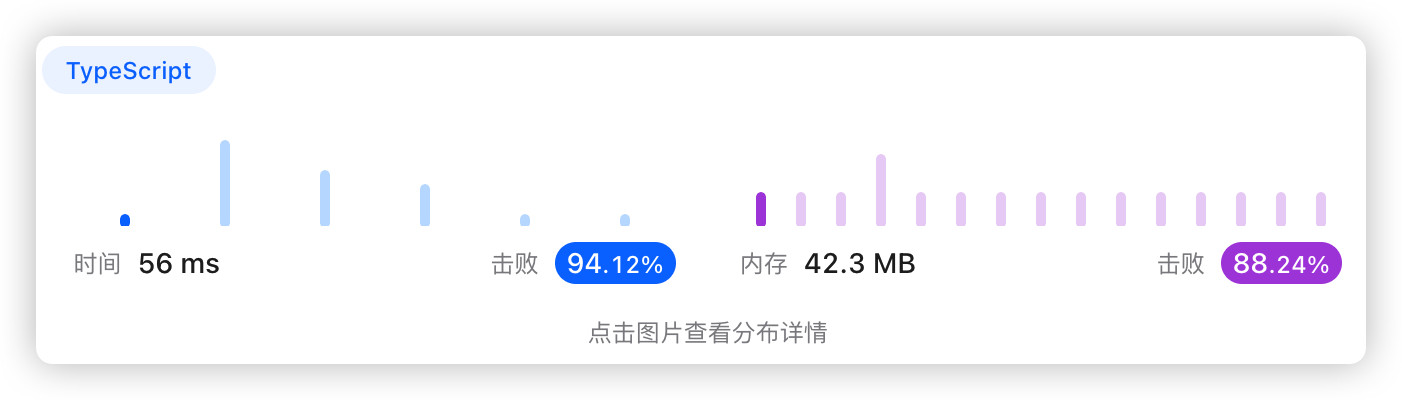
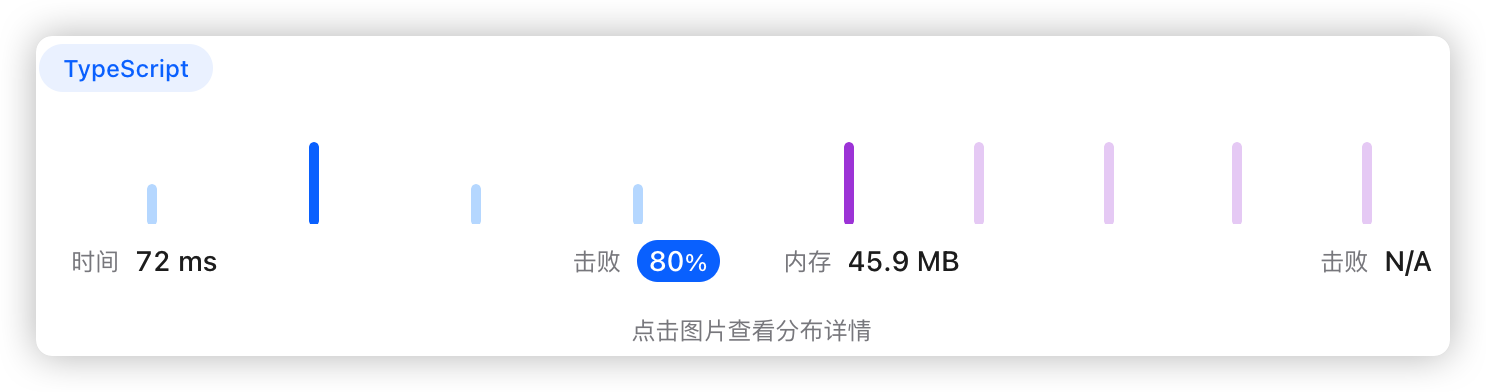
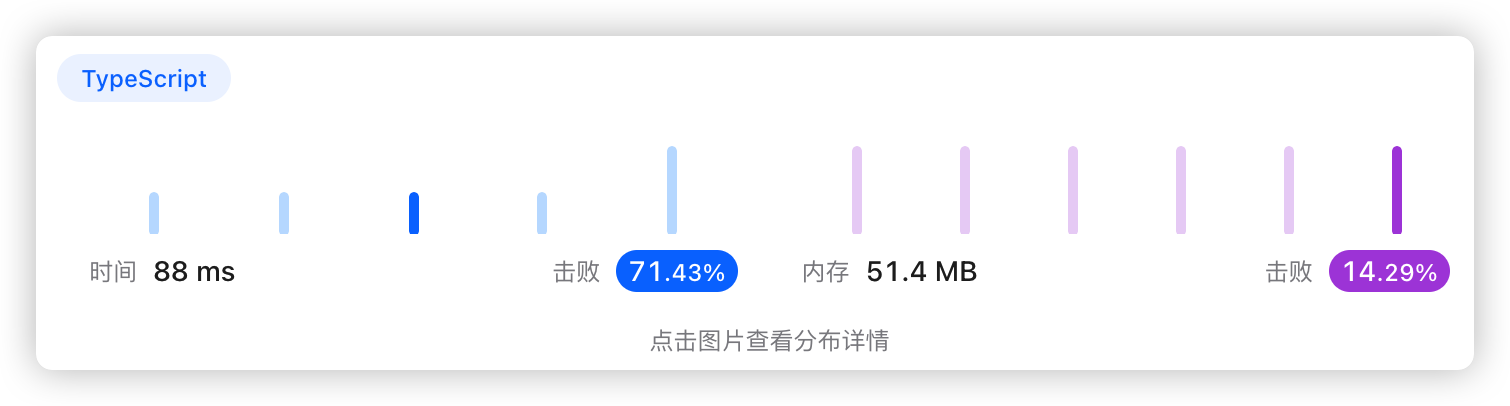
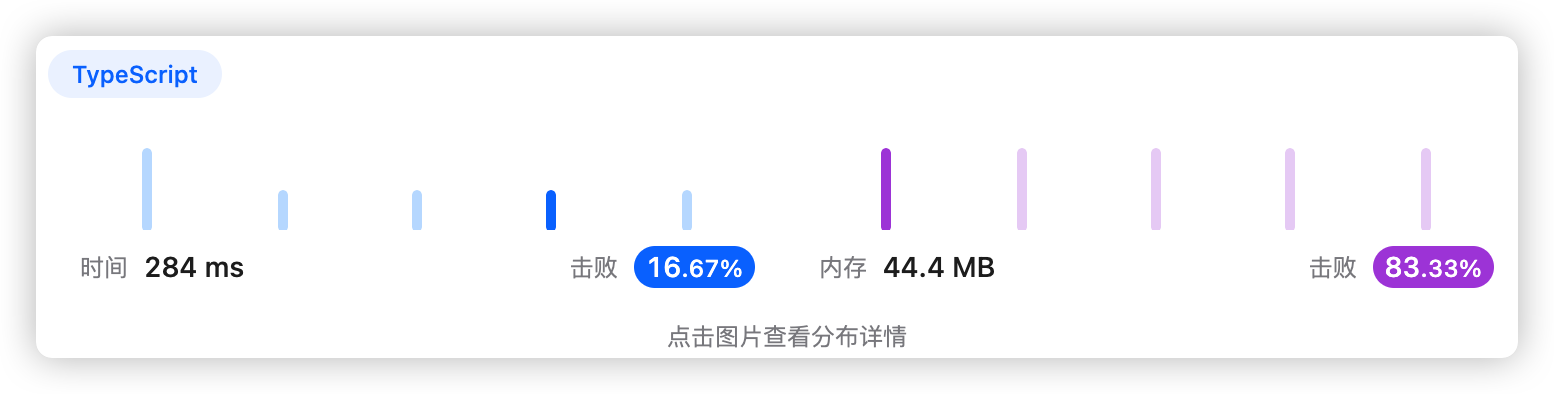
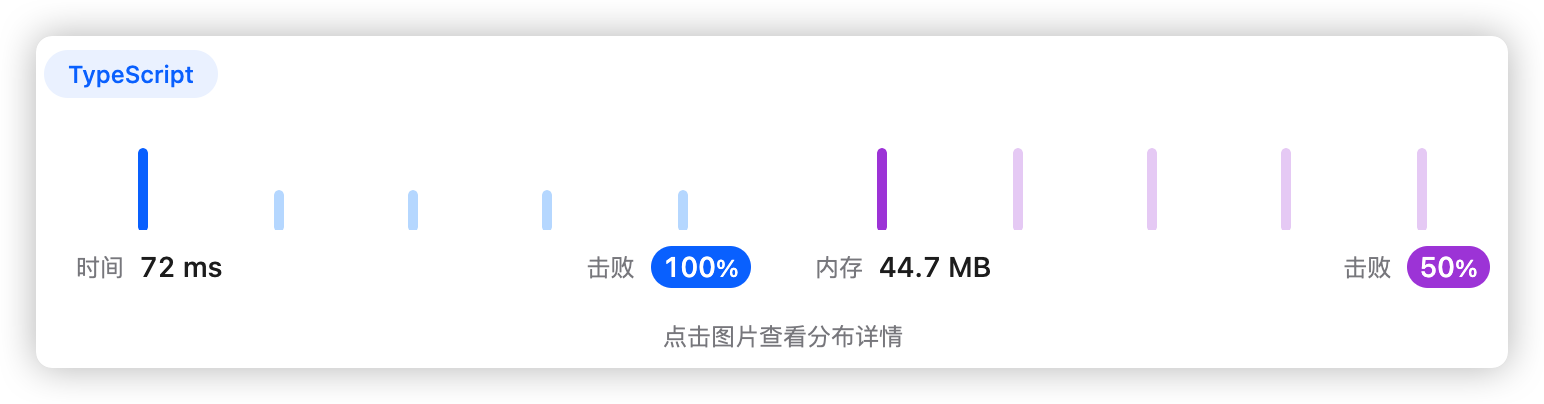
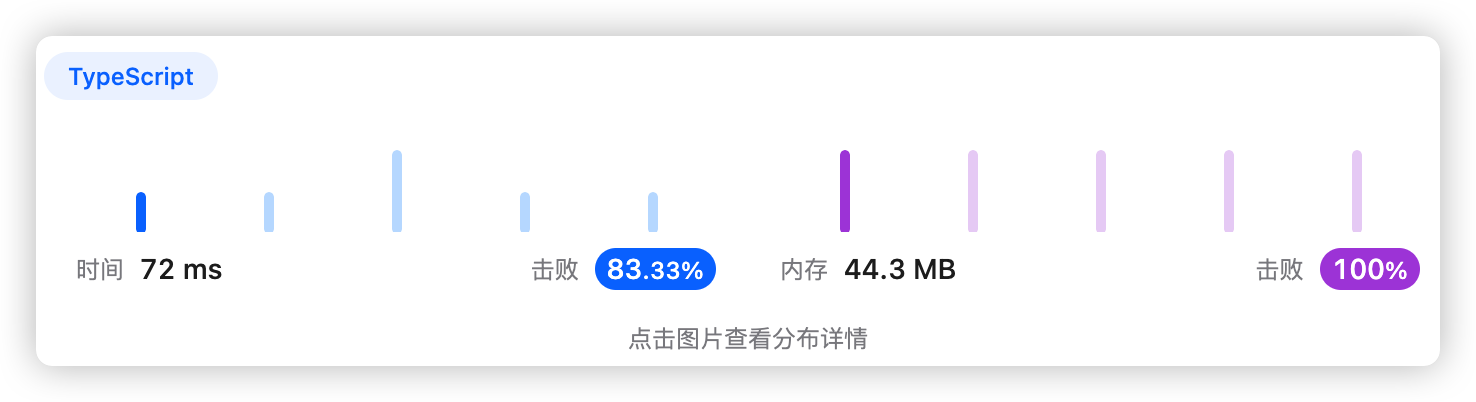
5、执行结果