1、题干
设计一个算法:接收一个字符流,并检查这些字符的后缀是否是字符串数组 words 中的一个字符串。
例如,words = ["abc", "xyz"] 且字符流中逐个依次加入 4 个字符 'a'、'x'、'y' 和 'z' ,你所设计的算法应当可以检测到 "axyz" 的后缀 "xyz" 与 words 中的字符串 "xyz" 匹配。
按下述要求实现 StreamChecker 类:
StreamChecker(String[] words):构造函数,用字符串数组words初始化数据结构。boolean query(char letter):从字符流中接收一个新字符,如果字符流中的任一非空后缀能匹配words中的某一字符串,返回true;否则,返回false。
示例:
输入:
["StreamChecker", "query", "query", "query", "query", "query", "query", "query", "query", "query", "query", "query", "query"]
[[["cd", "f", "kl"]], ["a"], ["b"], ["c"], ["d"], ["e"], ["f"], ["g"], ["h"], ["i"], ["j"], ["k"], ["l"]]
输出:
[null, false, false, false, true, false, true, false, false, false, false, false, true]
解释:
StreamChecker streamChecker = new StreamChecker(["cd", "f", "kl"]);
streamChecker.query("a"); // 返回 False
streamChecker.query("b"); // 返回 False
streamChecker.query("c"); // 返回n False
streamChecker.query("d"); // 返回 True ,因为 'cd' 在 words 中
streamChecker.query("e"); // 返回 False
streamChecker.query("f"); // 返回 True ,因为 'f' 在 words 中
streamChecker.query("g"); // 返回 False
streamChecker.query("h"); // 返回 False
streamChecker.query("i"); // 返回 False
streamChecker.query("j"); // 返回 False
streamChecker.query("k"); // 返回 False
streamChecker.query("l"); // 返回 True ,因为 'kl' 在 words 中
提示:
1 <= words.length <= 20001 <= words[i].length <= 200words[i]由小写英文字母组成letter是一个小写英文字母- 最多调用查询
4 * 104次
2、思路
- 构造函数:字典树存储所有单词的逆序串
- query:数组存储字符流,按字符流逆序查找字典树中是否存在该后缀
3、代码
class StreamChecker {
letters = [];
trie = { end: false };
constructor(words: string[]) {
for (const word of words) this.add(word);
}
query(letter: string): boolean {
this.letters.push(letter);
return this.find(this.letters);
}
add(word: string) {
let t = this.trie;
for (let i = word.length - 1; i > -1; i--) {
if (!t[word[i]]) t[word[i]] = { end: false };
t = t[word[i]];
}
t.end = true;
}
find(letters: string[]) {
let t = this.trie;
for (let i = letters.length - 1; i > -1; i--) {
t = t[letters[i]];
if (!t) return false;
if (t.end) return true;
}
return t.end;
}
}
4、复杂度
- 时间复杂度:构造函数 ,query ,其中 n为单词数,m 为单词长度,k 为查询次数
- 空间复杂度:
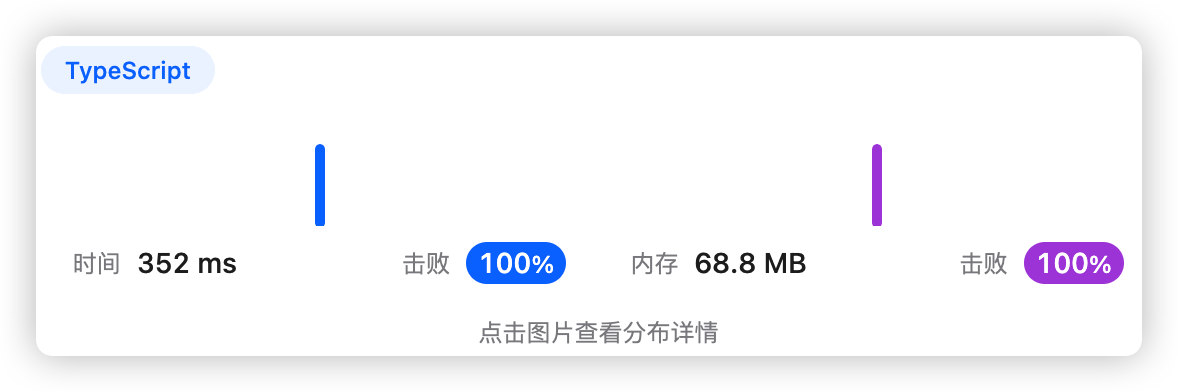
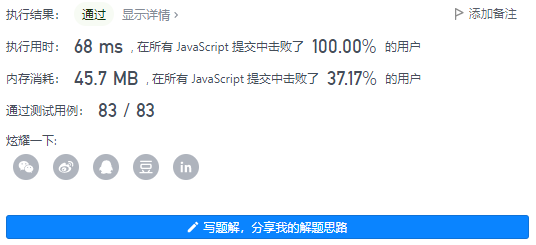
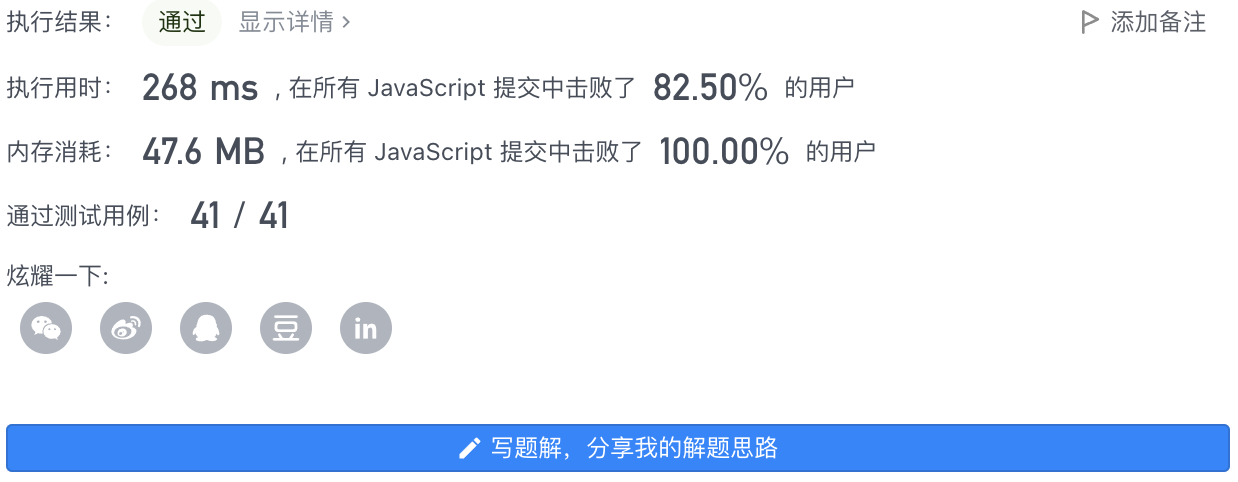
5、执行结果