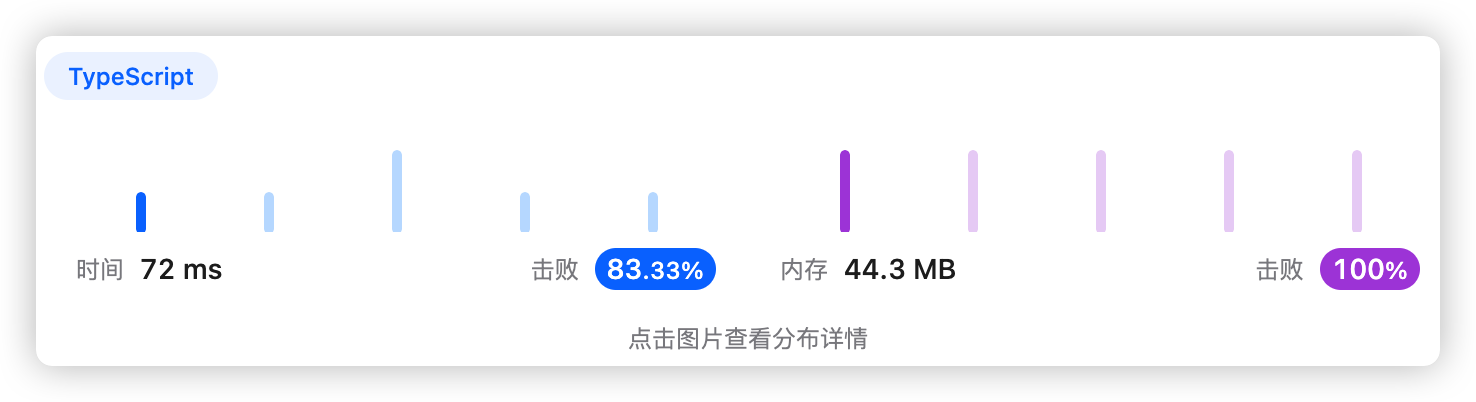
1、题干
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
提示:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-109 <= nums1[i], nums2[j] <= 109
进阶:你可以设计实现一个时间复杂度为 O(m + n) 的算法解决此问题吗?
2、思路
两种思路:双指针,合并后排序(无脑暴力)
3、代码
- 双指针
function merge(nums1: number[], m: number, nums2: number[], n: number): void {
const arr1 = nums1.slice(0, m), arr2 = nums2;
for (let k = 0, i = 0, j = 0; k < m + n; k++) {
nums1[k] = j >= n || arr1[i] <= arr2[j] ? arr1[i++] : arr2[j++];
}
};
官解的逆向双指针更优秀,空间复杂度为 ,即不需要另外开辟数组辅助,而是优先将结果填充到
nums1尾部区域
- 合并排序
var merge = function (nums1, m, nums2, n) {
nums1.splice(m, n, ...nums2);
return nums1.sort((a, b) => a - b);
};